Introdução
O objetivo deste artigo é orientar os usuários desenvolvedores de aplicações baseadas no Elipse E3, Elipse Power e Elipse Water (quando aplicável) sobre as boas práticas de estruturação, implantação e gestão destes sistemas. Com isso, visamos uma melhor compreensão, performance, facilidade de construção e manutenção, além da troca de dados entre aplicações E3 e entre outros sistemas.
As recomendações da estruturação aqui presentes estão de acordo com a norma ISA 95, cujo propósito é ajudar a definir padrões de interfaces de dados e suas funções. Esta norma segue o modelo de referência Purdue, que é um modelo de informação baseado na estruturação hierárquica do sistema.
Neste documento, utilizaremos modelos de dados do segmento de infraestrutura predial para fins de ilustração e exemplificação dos conceitos aqui propostos. No entanto, pode-se facilmente aplicar estes mesmos conceitos a outros segmentos da indústria.
Arquitetura de aplicações
As aplicações de sistemas de supervisão e controle com o Elipse E3 são desenvolvidas para trabalhar em dois cenários possíveis: aplicações locais, e aplicações distribuídas.
Aplicação Local
Uma aplicação local possui um único domínio e é responsável por todo o monitoramento dos dispositivos de campo (PLCs, IoTs, dentre outros). Neste tipo de estrutura, os dados estão concentrados localmente, conforme demonstrado no exemplo de estrutura a seguir.
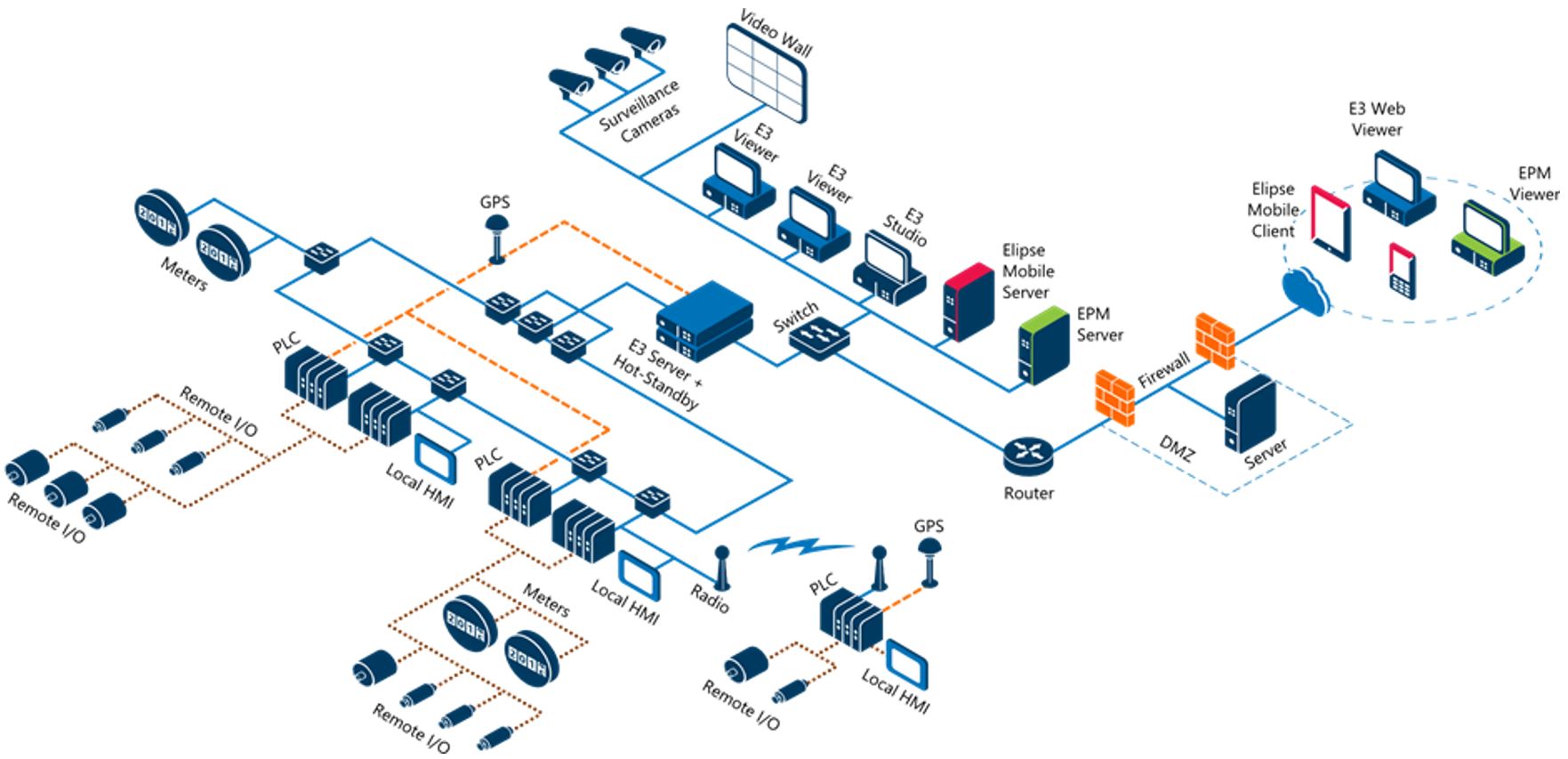
Aplicação Distribuída
Numa aplicação distribuída, temos dois ou mais domínios trocando dados entre si, e geralmente há uma aplicação central para monitoramento e/ou controle de toda a planta. Dessa forma, podemos ter aplicações locais, responsáveis por monitorar e/ou controlar um determinado processo, do mesmo modo como podemos também realizar estas mesmas funções através do centro de controle, mesmo que estejam geograficamente separados.
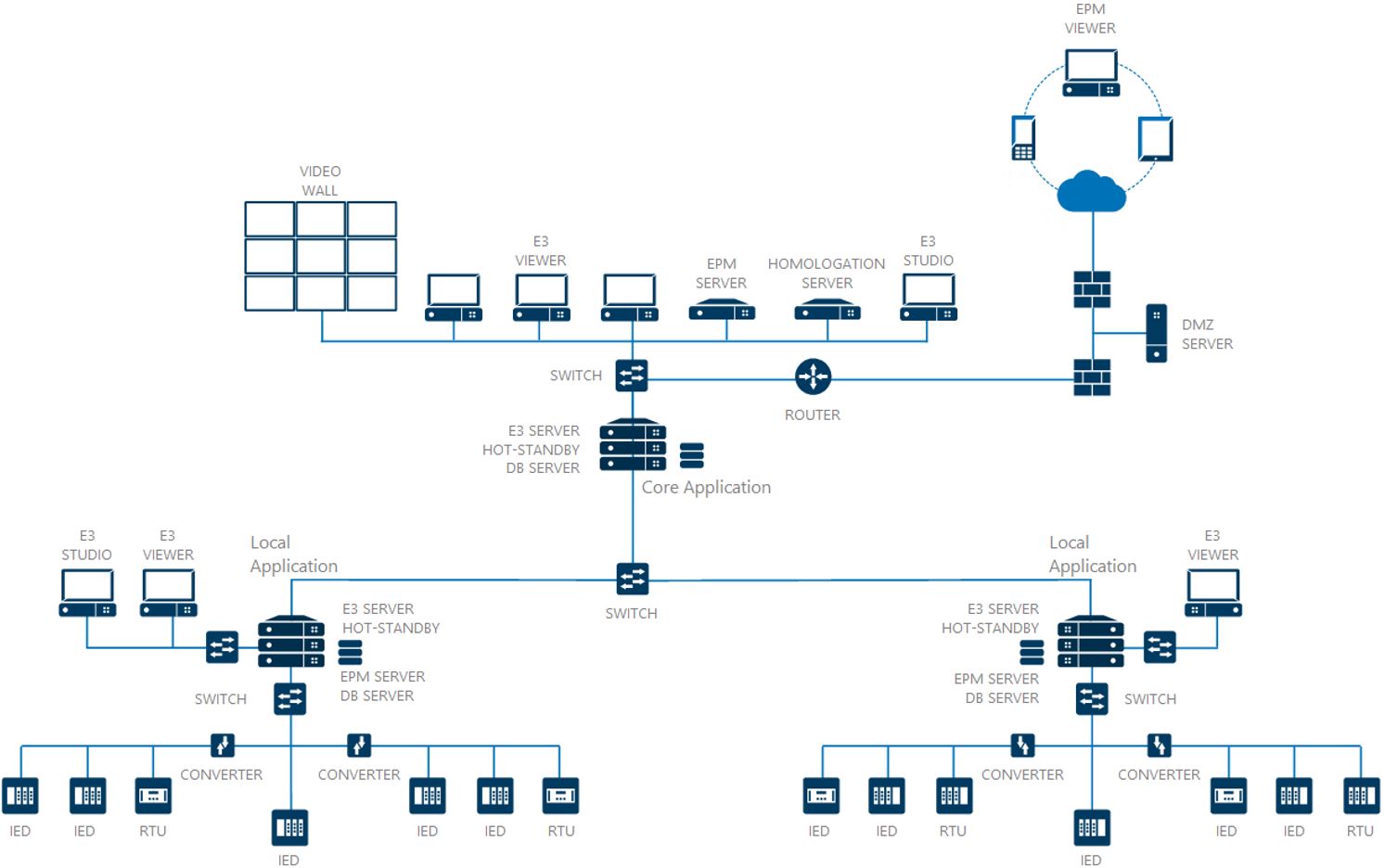
Neste tipo de arquitetura, é necessário atentar-se aos nomes dos objetos-raízes que são adicionados às estruturas dos projetos, inclusive o nome dos arquivos. Este cuidado deve acontecer para evitar o mau funcionamento do sistema. Outros pontos de alerta como este serão abordados nos próximos capítulos.
Gerenciamento dos arquivos de bibliotecas
Para arquiteturas distribuídas, a gestão dos arquivos de bibliotecas do Elipse E3 é um ponto bem importante. Na maioria das vezes, os mesmos arquivos são utilizados tanto em aplicações centralizadoras (centros de controle) como em aplicações locais (operação local). Portanto, é importante implementar no sistema uma rotina de controle de mudanças de arquivos e de controle de versão, a fim de garantir o perfeito funcionamento de todas as áreas da solução. Para este controle, é possível utilizar ferramentas como: Subversion, TFS, CSV, GIT e Mercurial, dentre outras. Assim, é possível controlar todas as mudanças de implementações, correções e melhorias, evitando conflitos de versões. Este mesmo procedimento também pode ser utilizado para os arquivos de projeto, garantindo então maior controle e qualidade das atualizações do sistema.
Para maiores detalhes sobre como realizar o controle de arquivos, recomendamos a leitura do artigo Controle de versões para arquivos de projetos de uma aplicação Elipse E3.
Troca de dados nas aplicações distribuídas
Na aplicação distribuída, é necessário escolher como será feita a troca de dados entre as aplicações. Dependendo do modo escolhido, alguns cuidados devem ser tomados durante o desenvolvimento a fim de garantir a fácil replicação dos arquivos entre um sistema e outro (local e distribuído).
Abaixo, descrevemos os tipos de trocas de informações possíveis. Também citamos quais cuidados eles exigem tanto para um bom fluxo de atualizações quanto para a adição de novos sistemas.
-
Comunicação direta com os controladores
Dentre todas as modalidades de trocas de dados entre aplicações Elipse, esta é a mais simples para o gerenciamento do fluxo de atualização dos sistemas. Neste formato, o mesmo driver configurado na aplicação local é replicado para a aplicação remota/centralizadora. Dessa forma, não é necessário realizar nenhuma configuração adicional durante o desenvolvimento da aplicação, pois essa mesma aplicação utilizada localmente pode ser migrada quase que totalmente para a aplicação central. Porém, para que isto aconteça, é necessário que o controlador seja multi-mestre, ou seja, um controlador que permita múltiplas conexões diretamente no equipamento.
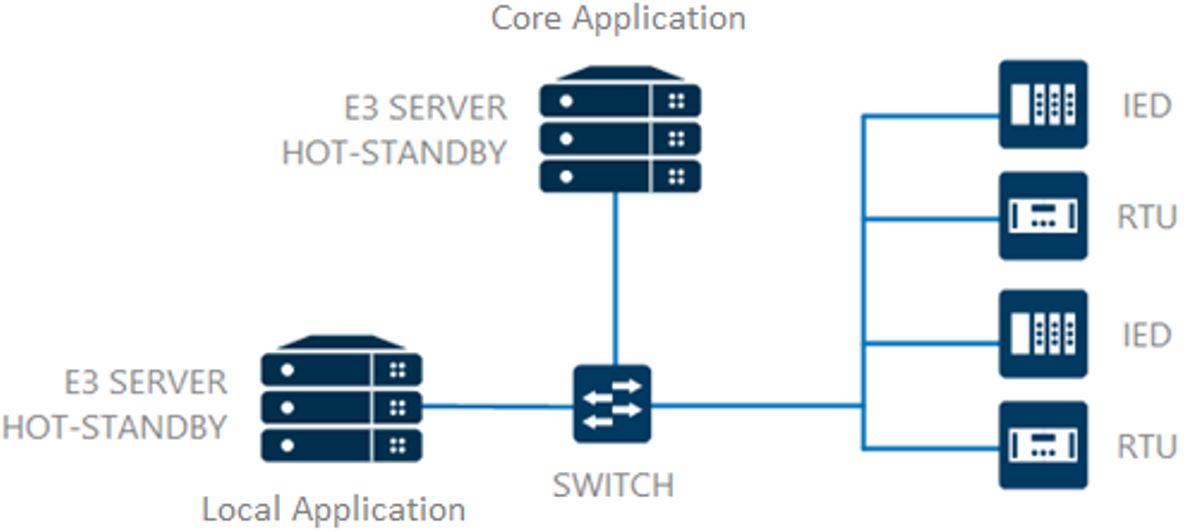
Figura 3 – Aplicações local e central comunicando diretamente com os controladores. -
Comunicação direta com o domínio local via driver
Neste modelo, a troca de dados entre aplicação central e as aplicações locais são feitas por meio de um driver de comunicação. Dessa forma, primeiramente a aplicação local realiza a comunicação com os controladores de campo. Depois, os controladores transferem estes mesmos endereçamentos para um segundo driver (escravo ou servidor), também configurado na aplicação local, e que servirá de ponto de conexão para a aplicação centralizadora. O fluxo de troca de informações acontece conforme apresentado a seguir.

Figura 4 – Os controladores trocam dados com a aplicação local, que replica as informações para a aplicação central via driver de comunicação. Isto pode acontecer de duas formas:
a. O protocolo (driver) que coleta as informações dos controladores é o mesmo protocolo do driver slave, que fará a conexão com a aplicação central. Na configuração deste driver, é necessário apenas assegurar-se que as parametrizações do slave permaneçam iguais às do equipamento. Assim, o projeto do driver de conexão será igual tanto para a aplicação local quanto para a central, facilitando a replicação dos projetos.
b. O protocolo (driver) da aplicação local que se conecta ao equipamento é diferente do protocolo do driver slave que fornecerá as informações para a aplicação central. Neste caso, será necessário reconfigurar o driver de conexão na aplicação central. Para isso, é possível ler os dados do controlador através do seu protocolo proprietário, e então configurar dois drivers slaves na aplicação local. Assim, a aplicação local terá dois drivers: um para configurar os dados de processo e outro para conectar com a aplicação central. Isto garante que o projeto tenha uma estrutura mais transparente de comunicação, dados e interfaces de ambas as aplicações, tornando a gestão de atualizações mais fácil.
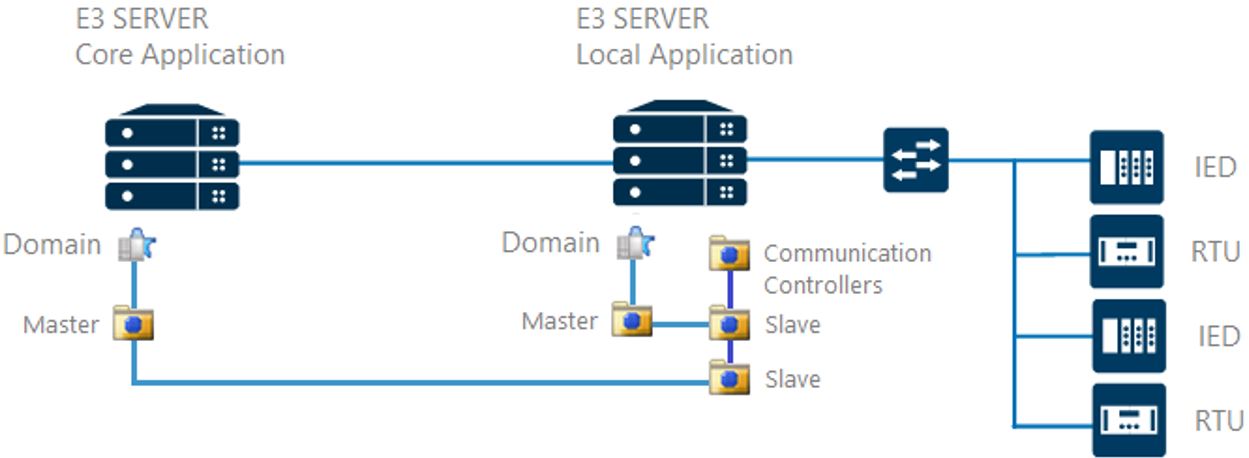
Figura 5 – Arquitetura de gateway de drivers Para maiores detalhes sobre aplicações gateways, recomendamos a leitura do artigo Elipse Gateway.
-
Comunicação entre aplicações através do protocolo OPC
Outra forma de trabalhar com os dados entre as aplicações e controladores é através do protocolo OPC. Neste formato, a aplicação local conecta-se aos controladores, e a aplicação central conecta-se à aplicação local por meio do protocolo OPC.

Figura 6 – Os controladores trocam dados com a aplicação local, que replica as informações para a aplicação central via driver OPC. Isto pode acontecer de duas formas:
a. Enquanto a aplicação local é construída para conectar-se diretamente ao controlador, a aplicação centralizadora necessita da configuração de um novo projeto de conexão com o driver OPC e a posterior substituição de todas as conexões para o padrão OPC. Para facilitar o trabalho de migração da aplicação local para a central, pode-se adotar um nome específico na pasta raiz da estrutura de dados (que nunca deve se repetir em outros níveis/pontos da aplicação), e realizar a substituição dos endereçamentos de todo o domínio através da ferramenta Procurar/Substituir. De todo modo, mesmo utilizando este recurso, é importante avaliar se todas as funções estão funcionando corretamente.
b. Outra possibilidade, que facilita a gestão das aplicações, é realizar a configuração da aplicação local, criando um “alias” OPC para a configuração de dados de todas as informações da aplicação. Dessa forma, bastaria apenas alterar o endereço de conexão do driver OPC na aplicação central.
-
Comunicação entre aplicações através do protocolo Domínio Remoto
O quarto e último formato possível para a troca de dados entre as aplicações locais e a aplicação central é através do protocolo de domínio remotos. Este protocolo é proprietário da Elipse; para maiores detalhes, acesse o artigo Domínios Remotos – Perguntas Frequentes (FAQ). Esta modalidade de troca de dados é similar à apresentada no tópico anterior (Protocolo OPC), porém ela não requer a criação de um driver e tags para retornar as informações de uma aplicação para outra. Isto acontece porque, neste protocolo, há acesso direto aos objetos da outra aplicação, ou seja, a aplicação local conecta-se aos controladores e a aplicação central conecta-se às aplicações locais.
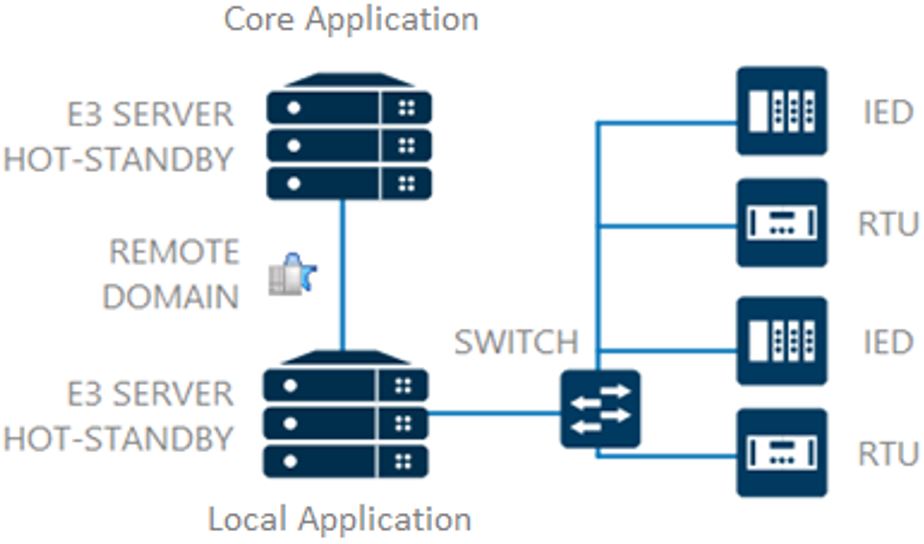
Figura 7 – Os controladores trocam dados com a aplicação local, que replica as informações para a aplicação central via Domínio Remoto. Para facilitar a gestão e o desenvolvimento das aplicações, recomendamos configurar o “alias” de conexão remota da aplicação local, ou seja, configurar a aplicação através dos endereços do domínio remoto. Para maiores informações, recomendamos a leitura do artigo Utilizando o recurso Alias Local na configuração de uma aplicação servidora de Domínio Remoto.
Dessa forma, é possível manter as configurações, de forma transparente, tanto na aplicação local como na central. Será necessário apenas, ao adicionar a aplicação local à aplicação central, reconfigurar o destino de conexão do domínio remoto.
Distribuição da estrutura da aplicação centralizadora
Quando a aplicação centralizadora possui uma quantidade relevante de dados e de processamento a serem realizados pelos objetos visuais e/ou servidor, recomenda-se, a fim de melhorar o desempenho da aplicação, as seguintes ações:
- Utilize a estrutura de plataforma de software na versão x64 (estas versões permitem utilizar uma quantidade maior de recursos do sistema operacional).
- Realize a divisão do processamento dos objetos visuais e do servidor do Elipse E3 em servidores diferentes.
- Monitore a forma de acesso dos objetos visuais aos objetos do servidor, principalmente para redes de baixa banda de tráfego de dados.
Para maiores informações sobre o assunto, recomendamos a leitura do artigo Melhores práticas para o desenvolvimento de uma aplicação Elipse E3.
Ferramentas do Elipse Studio
Verificador de erros
Para conferir a existência de problemas em aplicações Elipse, existe uma ferramenta nativa do Elipse E3 chamada Verificação. Com ela, é possível checar configurações tanto no domínio da aplicação como um todo, quanto em determinados arquivos (objetos).
Esta ferramenta aponta os problemas encontrados e exibe avisos (warnings) de possíveis problemas futuros da aplicação. Utilizamos aqui o termo “possíveis” porque existem configurações/programações de lógicas que se baseiam na existência prévia de determinados itens. Elas são resolvidas dinamicamente pela aplicação, mas que podem ser apontadas pela ferramenta como erros. Este tipo de notificação normalmente acontece em bibliotecas. Por isso, é importante compreender a aplicação como um todo para poder identificar, por meio da lista de erros, o que desconsiderar e o que efetivamente corrigir. Na maioria dos casos, o uso pontual da ferramenta, diretamente sobre os arquivos de projetos, pode ser a melhor opção para encontrar os erros de configuração.
Desfragmentação de arquivos
Arquivos de aplicação (projetos) são rotineiramente alterados e reconfigurados. É por isso que nestes casos, semelhantemente ao que ocorre no armazenamento de arquivos no disco do sistema operacional, novos espaços de armazenamento são alocados nos arquivos de aplicação. Portanto, a mera remoção de itens não libera seu espaço interno automaticamente. Dessa forma, nesta situação recomendamos a utilização da ferramenta de desfragmentação de arquivos, pois ela vai reconsolidar os itens que efetivamente estão sendo utilizados no projeto, e liberar os espaços ociosos.
Nomenclaturas
O primeiro passo para construir aplicações com segurança é atentar para o nome de todos os itens da estrutura, tanto o nome dos arquivos de projetos quanto o nome de itens raiz destes projetos (pastas, telas etc.). A ocorrência de nomes duplicados acarreta erros de utilização dos projetos/bibliotecas, fazendo com que eles não sejam executados. Dessa forma, dê preferência para nomes compostos unidos por underscore. Para composições muito grandes, utilize abreviaturas, sempre procurando entender se existe cobertura para os cenários de expansão do sistema.

Organização dos diretórios
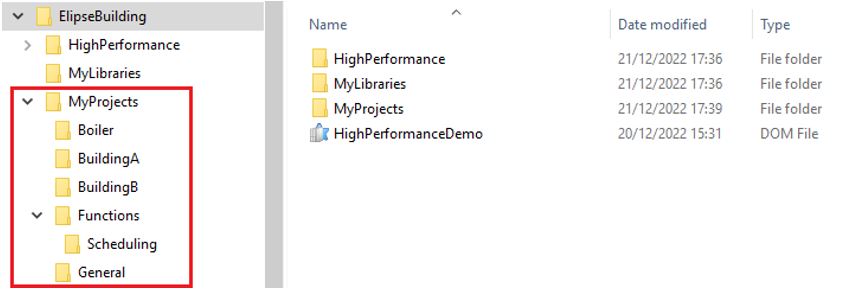
Outro fator a ser considerado durante a estruturação de um projeto é a forma de organização dos diretórios. Uma estrutura bem-organizada permite que arquivos sejam substituídos de forma muito intuitiva e simples, principalmente em um sistema segmentado ou distribuído. Vemos o exemplo de uma organização de diretórios para aplicações da área predial, onde todos os prédios, com seus respectivos arquivos, estão organizados de forma individual em pastas com nomes intuitivos e referentes ao ativo.
Organização de arquivos
Para uma maior eficiência incremental e de manutenção dos recursos da aplicação E3, recomendamos enfaticamente a segmentação do sistema em diferentes arquivos de projetos/bibliotecas, considerando as áreas supervisionadas e seu grau de relevância para o sistema. Ou seja, quanto mais separados os itens estiverem entre si, mais rápido será o processo de atualização e de inicialização do item durante a atualização, e menos impactos surgirão desnecessariamente em outras partes da solução.
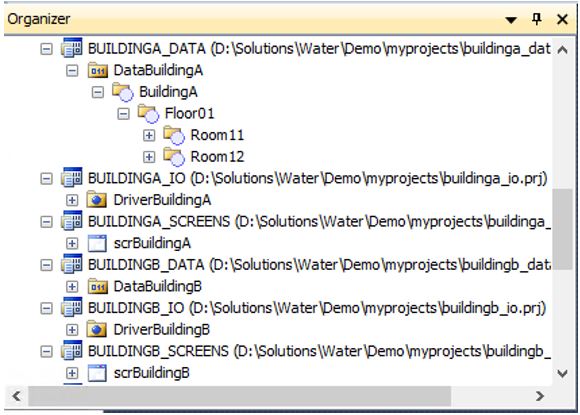
Conhecendo os objetos de dados
Antes de abordar a modelagem dos objetos de dados em si, é importante compreender, de forma global, como funcionam os objetos de dados das aplicações Elipse. Neste capítulo, portanto, descrevemos brevemente cada um desses objetos e qual a sua utilização.
Driver de comunicação
Drivers de comunicação são objetos que realizam a coleta das informações dos equipamentos de campo (normalmente, cada equipamento requer o seu próprio driver de comunicação) e o mapeamento de endereços/informações em tags ou blocos que vão interagir com o Elipse E3.
Através dos drivers, é possível ter acesso direto às informações, e por meio de suas tags, realizar as configurações de telas, alarmes, gravações etc. No entanto, não recomendamos esta prática, pois em diversos cenários, há a necessidade de se contextualizar determinadas informações das tags de comunicação. Por exemplo, quando realizamos a leitura de sinais digitais agrupados em palavras de registros (word e/ou dword), é necessário um contexto para saber o que cada sinal digital significa. Outro cenário comumente encontrado é o de um controlador que sozinho não representa toda a estrutura do sistema – dessa forma, o usuário precisará alternar entre diversos drivers para associar os tags a uma tela de processo.
Portanto, o driver de comunicação é a ferramenta de retorno dos dados do processo, e é nele onde se deve padronizar o retorno dos formatos de medidas/valores. Porém, para contextualizar a estrutura do processo em si, o melhor cenário é realizar a modelagem através dos objetos de dados do Elipse E3. Nos próximos capítulos, abordaremos as recomendações que dão contexto a essa estrutura de dados.
Configuração para padronização do formato do valor de leitura
Ao padronizar os valores que serão lidos/escritos pelo sistema, é possível ficar em dúvida sobre como ajustar os valores retornados nos tags para o formato padrão de trabalho da aplicação (por exemplo, como ajustar para que os valores de trabalho para a leitura de vazão sigam o padrão em l/s). Para utilizar a configuração padrão de valores da aplicação, recomenda-se ajustá-la diretamente nos tags de comunicação, através das propriedades de Escala.
Para mais informações, recomenda-se a leitura do artigo Trabalhando com escalas no Tag de Comunicação.
Tags Gerais
As aplicações Elipse também disponibilizam tags para uso gerais: são os chamados tags internos, demonstração, contadores e temporizadores, entre outros. Estes objetos, em alguns cenários anteriores, foram empregados na construção de estruturas hierárquicas, mas sua utilização torna a construção extensa, e muitas vezes “polui” o sistema, como vemos no exemplo demonstrado:
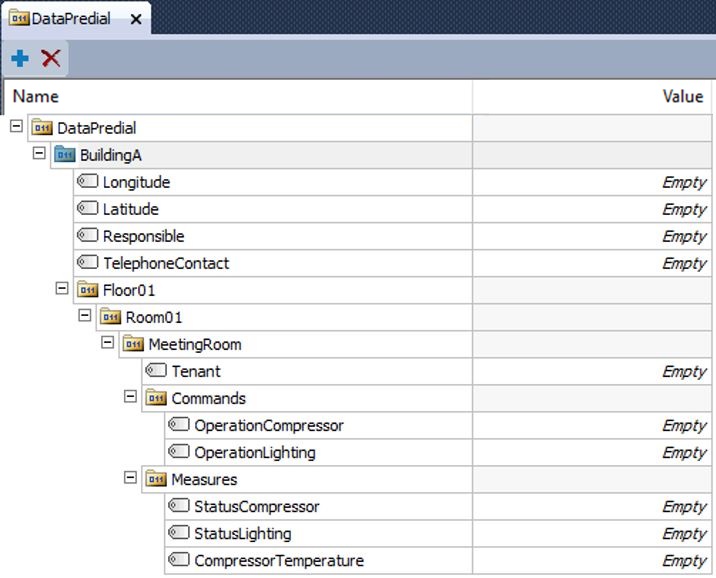
Com a criação do objeto XFolder na versão 4.8 do Elipse E3, não recomendamos mais a utilização destes tags gerais para a modelagem do sistema, apenas para usos restritos conforme a necessidade de cada projeto. No exemplo abaixo, é possível observar a troca da fonte de medida de acordo com a qualidade configurada.

Deste modo, recomendamos que as modelagens dentro do Elipse Power e do Elipse Water sejam realizadas utilizando seus objetos nativos. Já no caso do Elipse E3, o ideal é utilizar os objetos XFolder e XObject, respeitando e entendendo a funcionalidade de uso de cada objeto, o que será visto nos capítulos seguintes.
XObject
Com o XObject, é possível definir uma estrutura de dados que será executada no servidor. Tal estrutura pode realizar cálculos, associações, comunicações, verificação de alarmes e registros históricos, dentre outros. É importante notar que estes objetos possuem, em sua essência, a criação e utilização como uso fim de uma ação; por exemplo, uma máquina de controle com todas suas ações (comandos, medidas, alarmes etc.) criadas dentro deste objeto. Sua utilização não é desincentivada, mas atualmente, com a atualização dos objetos de modelagem, este objeto precisa ser empregado para agregar funções a objetos finais, a fim de conservar o máximo possível a modelagem hierárquica do sistema e compreensão da aplicação.
XFolder
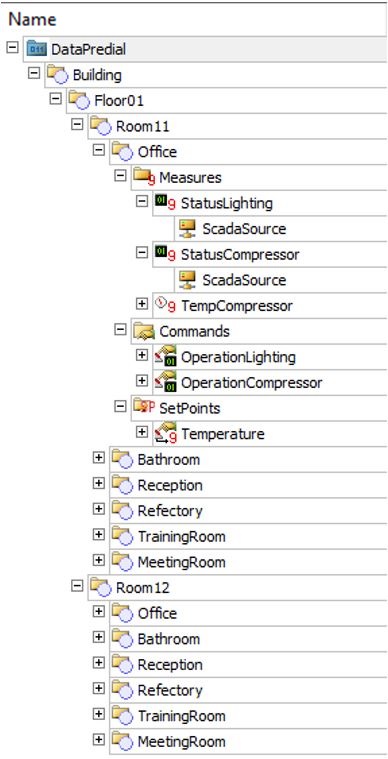
Um XFolder é um objeto de servidor que pode funcionar como “pai” de outros objetos externos. A partir dele, a hierarquia dos objetos fica mais organizada e transparente. Por exemplo, evita-se a necessidade de criar tags gerais (tags internos) para adição de informações, já que é possível adicionar propriedades a estes objetos de dados.

As vantagens de se trabalhar com estrutura hierárquica são:
- Permite alta flexibilidade na modelagem dos itens, pois é possível adicionar informações específicas para cada objeto/item em particular da aplicação.
- Retorna e avança entre seus níveis de forma fácil e transparente, o que permite um rápido acesso às informações necessárias.
Como realizar a modelagem de objetos de dados no servidor
Modelagem para aplicações gerais
Para realizar modelagens de sistemas Elipse em plataformas que possuem ferramentas específicas para o segmento (como por exemplo o Elipse Power, desenvolvido para sistemas de energia), recomendamos enfaticamente a modelagem do(s) sistema(s) através dos objetos nativos da plataforma.
No caso de modelagens de aplicações que não possuem objetos nativos, recomendamos modelar a aplicação através dos objetos da biblioteca PlantModel. Os objetos desta biblioteca permitem a construção de diversas aplicações gerais, independentemente do segmento, pois já contam com recursos bastante úteis para o processo, como rastreamento de execuções de comandos, configuração do historiamento de propriedades para o EPM, e outros. Há também a possibilidade de criar sua própria estrutura de objetos com os XFolder, respeitando a configuração hierárquica dos ativos, que é mais flexível e aderente à adição de funcionalidades futuras.
Para mais detalhes sobre a biblioteca PlantModel, recomenda-se a leitura do documento Manual PlantModel.
Dentro desta estrutura de modelagem hierárquica, pode-se realizar a construção do objeto final de operação (máquina, sensor e outros) de duas maneiras:
- Seguindo a construção hierárquica (XFolder), ou
- Modelando/concentrando as funções do objeto (XObject).
Deve-se escolher entre estas opções de acordo com as necessidades específicas de cada aplicação. No entanto, leve em conta que com a construção hierárquica, é possível visualizar a estrutura do sistema como um todo e ajustar facilmente sua hierarquia, além poder contar com recursos nativos já fornecidos pelas bibliotecas da Elipse, como o Elipse HighPerformance. Através deste recurso, é possível por exemplo dispor de uma tela nativa, chamada Faceplate, para a operação de um ativo.
Telas de operação personalizadas, ou com modelos de objetos não suportados pelo Faceplate, devem ser criadas por um programador.
Como adicionar funcionalidades de estrutura de dados na aplicação
Para adicionar funções ao sistema, reforçamos as recomendações expressadas nos tópicos anteriores deste documento, ou seja: sempre que possível, as funcionalidades devem ser independentes entre si. Isto significa que a cada nova função adicionada ao sistema, as estruturas de arquivos de projetos/bibliotecas devem ser distintas, para que suas atualizações, correções e melhorias não interfiram no funcionamento dos demais processos ou do sistema como um todo.
Como organizar os alarmes na aplicação
É possível configurar os alarmes da aplicação de duas maneiras distintas: através da estrutura hierárquica entre objetos, ou através da adição direta na seção de alarmes do sistema. Abaixo, listamos as vantagens e desvantagens de cada abordagem.
- Alarmes na estrutura hierárquica:
Vantagem: facilidade para ajustar as configurações das áreas de alarmes (por exemplo, a partir do contexto ou da posição hierárquica mantidas por cada alarme).
Desvantagem: dificuldade para encontrar os alarmes na área de edição (E3 Studio), sendo necessário em alguns casos utilizar ferramentas de suporte, como códigos no E3 Studio ou banco de dados. - Alarmes na estrutura padrão de alarmes:
Vantagens: fácil localização de toda a estrutura de alarmes; possibilidade de separação dos itens em arquivos diferentes.
Desvantagem: maior tempo de configuração e atualização de uma grande quantidade de alarmes.
É possível também configurar alarmes dentro de estruturas de XObjects. Abaixo, listamos as vantagens e desvantagens desta abordagem.
- Vantagem: os objetos modelados desta maneira já possuem configuração de alarmes: caso haja necessidade de alguma alteração, ela pode ser realizada diretamente na classe, assim todos os objetos serão atualizados.
- Desvantagens: não é possível salvar ou realizar alterações particulares de forma nativa, somente através da estrutura de apoio no objeto; difícil localização de todos os possíveis alarmes do sistema.
Todas as abordagens acima podem ser utilizadas sem maiores problemas. Porém, para que o sistema seja mais facilmente compreendido por usuários de todos os níveis, recomendamos modelar os alarmes de sua aplicação através da estrutura padrão de alarmes.
Como realizar o armazenamento das informações
Uma das funcionalidades cada vez mais essenciais em um sistema de automação é o armazenamento das mudanças dos tags (historiamento). Através dele, é possível compreender tanto o funcionamento passado quanto o atual da operação, bem como realizar projeções futuras que permitam realizar ações para melhorá-la cada vez mais. Neste cenário, o uso da plataforma Elipse Plant Manager (EPM) é fundamental. Com ela, é possível agregar diversas funções de gestão de dados, análises e melhorias contínuas no sistema, trazendo maior inteligência operacional ao processo.
A plataforma EPM também disponibiliza ferramentas para gravação automática dos dados da aplicação através da biblioteca PlantModel. Com ela, é possível selecionar diretamente na definição do objeto/medida quais medidas serão gravadas no EPM ou não, através da propriedade EnableHistorian.
Para maiores informações sobre o EPM, recomendamos a leitura dos artigos sobre o Elipse Plant Manager.
Como criar interfaces de telas
A criação de interfaces operacionais pode se dar de diferentes modos: criando a estrutura de visualização diretamente na tela, utilizando uma biblioteca com os XControls, ou mesmo trabalhando com camadas ou com visibilidade. É possível aplicar qualquer um destes modos para construir a interface, mas observe estas orientações:
- Evite construir interfaces visuais duplicadas através de uma construção indexada da interface (por exemplo, duas interfaces iguais de comandos de um mesmo motor).
- Utilize o menor número possível de scripts, e priorize o uso de associações.
- Evite acessos constantes ou em grande escala aos objetos do servidor. Neste caso, recomendamos trabalhar com o tráfego da estrutura do servidor via arquivo estruturado.
Procedimentos de atualização
Uma vez que a aplicação esteja em execução, deve-se evitar ao máximo que o domínio seja interrompido, pois todas as atualizações de objetos no Elipse podem ser realizadas em tempo de execução, principalmente arquivos de projetos.
Caso seja necessário, é possível também parar um único arquivo. Conforme o exemplo abaixo, é possível fazer a parada específica do projeto daquela região sem impactar as demais áreas.
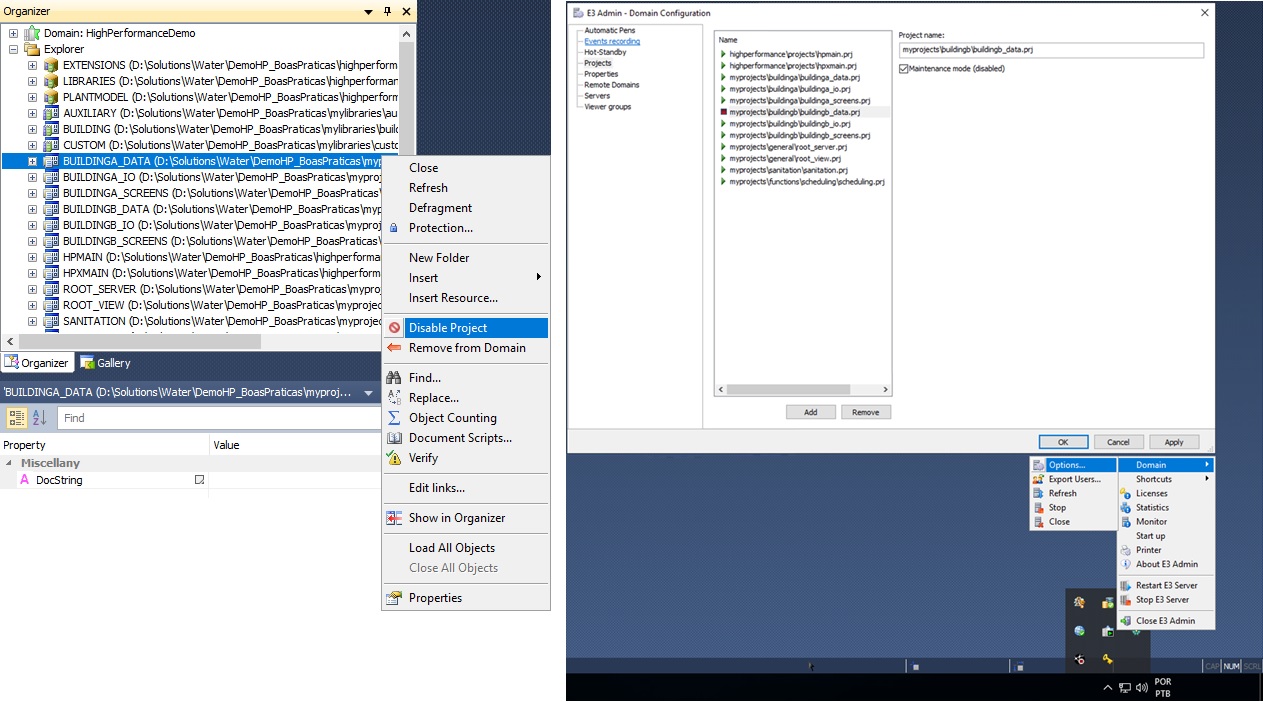
Também é possível atualizar as bibliotecas em tempo de execução. Porém, se objeto para atualização estiver sendo utilizado por mais de um projeto ao mesmo tempo, todos eles serão reiniciados. Neste caso, recomendamos agendar as atualizações.
Para maiores informações, recomendamos a leitura dos seguintes artigos:
- KB-32358: Atualizando a aplicação sem que o Domínio precise parar.
- Manutenção remota de aplicações no Elipse E3.
HotStandby
-O HotStandby permite que um failover seja implementado em um sistema supervisório. Um failover implica na existência de dois servidores, um deles principal e o outro deles de backup, ambos mutuamente contingentes. Ou seja: caso o servidor principal venha a falhar, um servidor de backup entrará em ação imediatamente para substituí-lo, sem perda da continuidade do processo.
Para maiores informações sobre este assunto, bem como para uma demonstração de como são feitas as atualizações de arquivos nesta estrutura de sistema, recomendamos a leitura dos seguintes artigos:
Anexos:
