1) INTRODUCTION
The constant need for improvement in productive processes, including the pressure for lower costs and shorter deadlines, requires us to have increasingly more information about everything taking place in an industrial plant.
In this context, there is an ever-growing need for systems that concentrate in historic databases all the data collected from heterogeneous sources of information, such as SCADA systems and PLCs from different vendors, in order to create a central repository that allows developing intelligence on the process.
Such systems, known as PIMS (Plant Information Management Systems), allow you to turn raw data into process intelligence by:
- Eliminating information islands.
- Integrating systems such as ERP and Supply-Chain, among others, with the plant floor.
- Performing calculations with the collected data.
- Spreading information with collaborators, who then will be able to, among others, obtain performance or efficiency indicators, compare production batches, view synoptic charts of different parts of the plant simultaneously, etc.
PIMS software systems allow you to store analog, digital, and string data, as well as other types of sound and image files. The vast amount of data, in addition to the long period required for storing it (five or more years) and the need to be able to retrieve it quickly, stand as a great challenge for historian systems.
To reproduce the original data more accurately, as well as to decompress it more quickly, PIMS systems present the “Temporal Database” concept. This means that each collected sample will have its value, timestamp, and quality processed, in order to indicate the sample’s quality. Thus, the database is created internally, which facilitates searching for a values sequence in the same variable.
2) PROPRIETARY DATABASE TECHNOLOGY
Because of the performance needs stated above, some historian software vendors opted for developing their own database technology. This means that the vendor is the only one that knows how the storage effectively works, and in turn will (theoretically) get higher access speed due to the absence of overheads in the database’s abstraction layers.
An example of proprietary database can be seen in Figure 1 below, where each fileset correspond to a certain data period. Usually, there is the “active” fileset, where current data is inserted, and the filesets from previous periods, which may be either available (assembled) or unavailable (disassembled) for query. The latter ones are used for long-term storage.
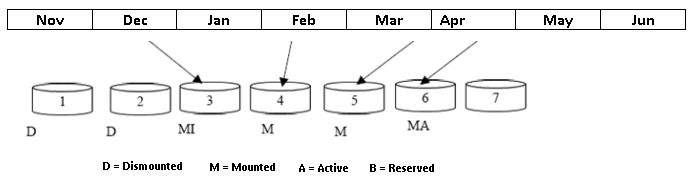
Figure 1: Organizing filesets in a PIMS system
Each fileset stores the records from each variable in the temporal system, that is, it groups several collections from the same variable sequentially, in a compressed way.
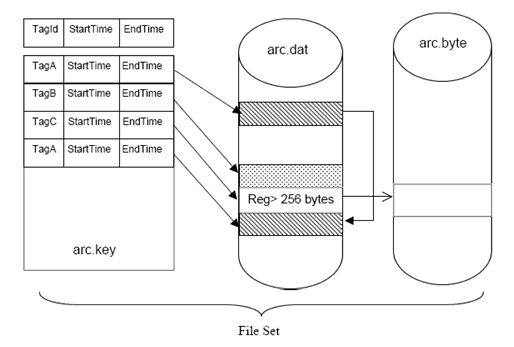
Figure 2: Organizing filesets internally in a PIMS system
In order to supply data to other systems, historians will display access interfaces. One of these is OLE DB, standard interface used for Windows programs to access a relational database, which is a traditional method of accessing Databases. With this, you will be able to use SELECT and UPDATE operations, for example.
However, even in an OLE DB interface, the historian’s hub (PIMS) is still part of the transaction, which means that even after data is queried in the proprietary database, it will still be manipulated by the hub, because it needs to be decompressed or manipulated in order to be delivered to the interface. This architecture is seen in Figure 3.
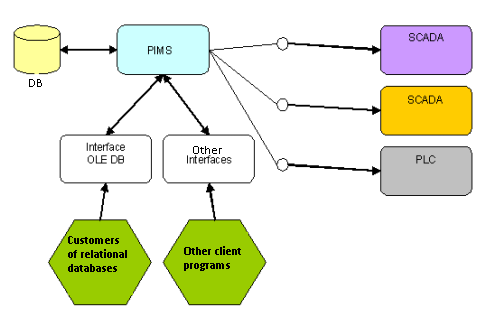
Figure 3: Traditional PIMS systems’ architecture
3) NON-PROPRIETARY DATABASE TECHNOLOGY
Other PIMS system vendors, however, opt for using a commercial database for data storage, usually Microsoft SQL Server®. Even though SQL Server (just as most of the commercial databases) offers a well-known internal architecture (databases, tables, stored procedures, etc.), higher performance requirements lead to the creation of rather complex temporal structures on the tables.
As seen in Figure 2, compressing each sample’s value + timestamp + quality information make accessing a PIMS’s SQL database a nearly impossible task. This means that, for a client to access historic data as SQL queries, the data must pass, as in the previous model, through an OLE DB interface, which still requires the PIMS hub for decompressing or transforming data.
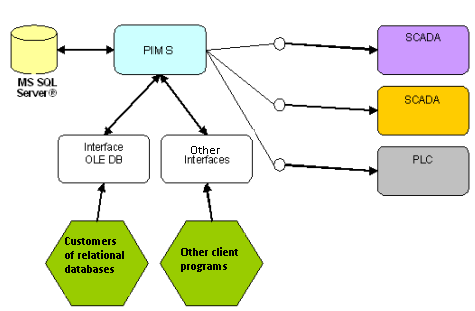
Figure 4: PIMS systems’ architecture based on MS SQL Server databases
4) DEVELOPED APPROACH
For this article, we have adapted a non-proprietary technology (using commercial databases) assuming that the format of the stored data is publicly known and easily accessible. This means that any program, as long as properly authorized by the administrator, is able to access the temporal/relational database directly and extract the desired information, with no help from the PIMS hub or a specific OLE DB interface. This can be seen in Figure 5.
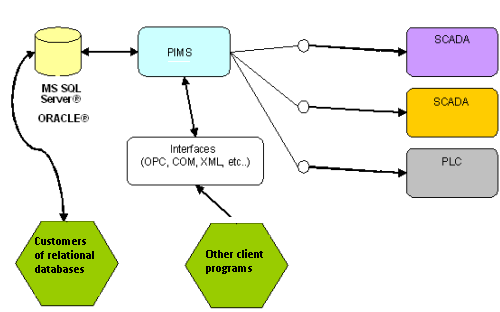
Figure 5: Newly developed PIMS architecture
As seen above, there is still some degree of freedom of access to the stored information, since no extra licenses are required to access the PIMS hub, since each client will access the database directly (Microsoft SQL Server® or Oracle®).
5) TABLE STRUCTURE
The methodology used for storing data is based on establishing storage modules, called E3Storages. Each E3Storage allows you to configure a set of storage variables, which can be analog, digital, or string (simultaneously). In addition, each E3Storage has its own base-name for the table, which will be used for storing data after being processed by the compression alarm.
However, to keep a compromise between giving easy access to external clients and maintaining a good performance for recording and retrieving data, each E3Storage displays a system of main a backup tables, as seen in Figure 6.
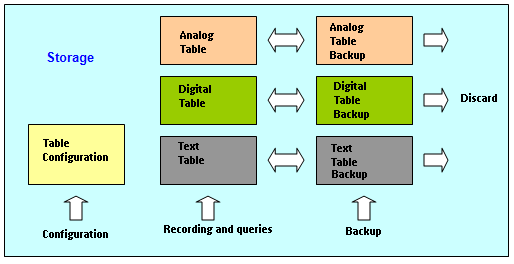
Figure 6: E3Storage table structure
The main table, containing a user-defined data period, is where recently collected data is inserted. It also allows querying it either via PIMS hub or via other clients. Data in this table is in a hybrid format between Relational and Temporal modes, but it is uncompressed. Each record’s format is:
On the other hand, the backup table contains the data discarded by the main table, also within a user-defined period. However, the backup table’s format is not the same as the main one’s, since in order to save space in disk, the data stored here are actually temporally compressed, while in the main table they are pseudo-temporally uncompressed.
In the developed architecture, the PIMS hub is the only one able to access the backup tables, either by compacting the data in the main table that exceed the maximum desired time, either by uncompacting an older backup period (as required by a user) and reinserting this data temporarily in the main table.
The user can set up how often the exceeding data will be transferred from the main to the backup table, and how often data will be discarded from the latter (for example, every 24 hours).
The field configuration table, seen in Figure 6, is where each field’s configurations are stored. The main feature in this table is linking a unique index for each stored variable, which will be used in both main and backup tables for identification purposes.
6) COMPRESSION ALGORITHMS
As values being collected are received by the PIMS hub, each point’s need to be recorded is gauged. This happens because if the variable doesn’t change (or if it changes very little) at each time period, you will only need to store its rate of change, and not all repeated data, which would clutter the database.
Thus, for each variable you wish to store, you will need to set up its type (analog, digital, or string); for analog variables, you will also need to set up a dead band value (in percentage or in absolute values), and the recording’s minimum and maximum time.
In this case, we used the BoxCar/BackSlope algorithm to gauge the need for recording at every individual point, as seen in Figure 7.
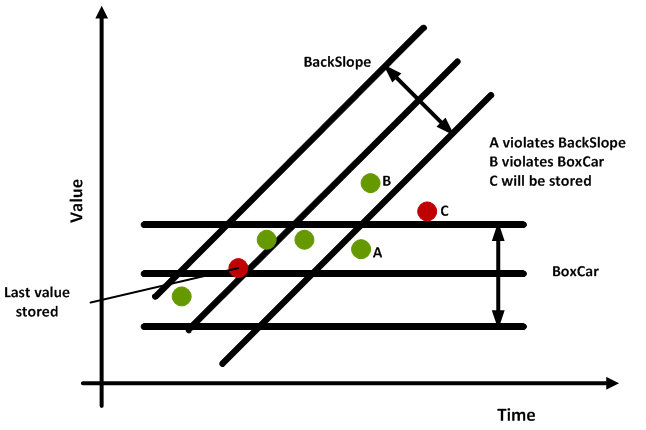
Figure 7: BoxCar/BackSlope algorithm
From the informed bandwidth, the algorithm establishes a horizontal variation limit related to the last stored point (BoxCar). At each new reported point, diagonal variation limits are calculated, using the same bandwidth (BackSlope).
Generally speaking, whenever a point violates two imaginary areas established by BoxCar and BackSlope lines, the point must be stored.
Exceptions to the rule above happen whenever the point changes quality, or then when the maximum time since the last recording was surpassed – in these cases, the point is always recorded.
7) QUERYING THE DATABASES
Although the format of the data in the main table is very simple, querying it directly can be a rather arduous process:
- Given a variable in the system, you will need to obtain the index to be linked to the variable.
- Given initial and final intervals, you will need to select the records whose index is the same as the one obtained previously, and also to define whether only GOOD quality records are to be included.
To make this process easier, and to allow basic data manipulation, a few Stored Procedures are available for immediate retrieval, which will facilitate the process. They are:
- Last value
- Stored value of a date/time
- Tag attribute
- Values stored from a date/time
- Values stored in a date interval
- Values sampled/interpolated in a date interval
- Values calculated in a date interval (maximum, minimum, average, median, etc.)
8) EXAMPLE OF ACCESS VIA ELECTRONIC SPREADSHEETS
In the figure below, we see an example of how to access the PIMS data via Microsoft Excel. A macro was developed to allow connecting to the database directly, consolidating the Stored Procedures’s data.
Figure 8: Excel’s macros for accessing PIMS data
9) FINAL REMARKS
This articles illustrates how developing a PIMS system, whose information can be accessed in a more democratic way by several different clients, allows you to increase the possibilities of integration. The database can be purchased from one of the two main vendors in the market. Additionally, we have seen how the chosen algorithm (BoxCar/BackSlope) allows you to reduce the database size in approximately 90% more when compared to conventional relational historians.
The format being use (temporal) allows several consolidations, calculations, and even applications to be developed based on stored data, working as a foundation to implement many different operational intelligence systems.

What is the purpose of using data compression algorithms, such as the BoxCar/BackSlope algorithm, in process historians, and how do they improve database storage efficiency?