1) Introduction
Due to their flexibility, SCADA (Supervisory, Control and Data Acquisition) systems can be used in a great variety of processes, which include its application as an operational analysis tool, depending on the process conditions, but mainly in data acquisition and monitoring. Usually, SCADA systems are used efficiently when there are a great number of variables to be collected in relatively small intervals (seconds, generally).
For some applications, such as vibrating systems, you must have specific equipment and software for higher efficiency, with fewer variables and smaller rates (milliseconds). However, this does not prevent SCADA software from connecting to any type of system (including quick monitoring systems), as long as it focuses on operational and administrative level information. An example is collecting disturbances in protection relays, known as COMTRADE files. These files contain a snapshot of a period of time when the system being monitored presented a disturbance. Although they show data in a resolution of milliseconds, it is still possible for a SCADA system to capture these files after the disturbance, for analysis in the system’s own consoles.
2) Current systems’ architecture
In modern SCADA systems, working with the concept of servers and operation consoles, the processing distribution has a very flexible architecture, capable of allocating all main monitoring and supervisory tasks in one computer, or separating main activities into several units, with the option of native redundancy in each one. An example of this architecture can be seen in Figure 1.

Figure 1: Example of SCADA system’s settings using Elipse Software’s E3
Data acquisition can occur via any OPC server, or via native I/O drivers, which allow optimization in communication and configuration flexibility, even online. Servers can be allocated for these processes’ execution only, to report changes in data to other machines via OPC or other protocols over TCP/IP. These protocols work in exception mode, reporting data in VQT standard (Value, Quality, and Timestamp).
3) Why use redundancy?
When SCADA systems adopted the concept of thin clients, as opposed to the traditional rich client architecture (where each SCADA station must have a non-synchronized copy of the whole database), some technicians started to criticize this new philosophy for centralizing the system’s main activities in a single server, thus creating a vulnerable spot.
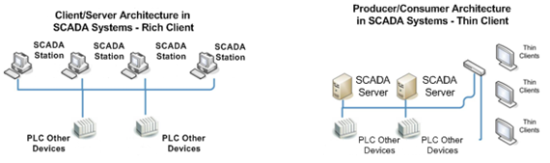
Figure 2: Traditional Rich Client architecture versus Thin Client architecture
The solution for this problem was to create a native redundancy mechanism for the servers, so that there is failover (servers’ switchover), the client stations (thin clients) automatically redirect traffic to the new active server. In the architecture displayed in Figure 1, it is possible to see an example of redundancy in servers that consolidate and distribute data.
Redundancy in acquisition devices is also supported. Thus, I/O drivers can switch to the next available device when a specific failure is reported, and not only when there are communication errors.
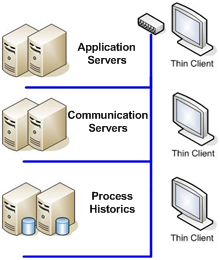
Figure 3: Distribution of activities in redundant pairs
Going into the details of the solution, through the use of mechanisms of database and file synchronization, it is possible to distribute parts of tasks from a complex system to several servers, with the option of redundancy in pairs. This way, you can maintain the benefits from the former architecture, such as the automatic screen synchronism among all operation consoles, as well as other maintenance facilities.
4) Triple redundancy architecture
For systems where the main problem is not exactly the size of the application, but the need for a 24×7 operation with MTBF (Mean Time Between Failures) of many years, i.e., with a higher level of integrity, some users may opt for a triple redundancy architecture for the servers.
However, the only practical reason to use this architecture in terms of SCADA servers is the fact that whenever there is a failure in the server (and while it is being repaired), the operation is centralized in only one server, and a third machine should assume the standby functionality.
On the other hand, this is very unlikely to happen, since there are market solutions which allow this configuration. The question is that if, for some reason, the MTTR (Mean Time To Repair) is high, it may be worth keeping another machine in standby, ready to take over when necessary.
One of the possible architectures for this shows a main server, an active or “hot” standby server (with or without active I/O drivers), and a third inactive or “cold” server. Thus, in case of unavailability of the main server, the standby server becomes the main server, and the inactive server becomes the active standby server, in case the damage in the first server is enough to take that action.
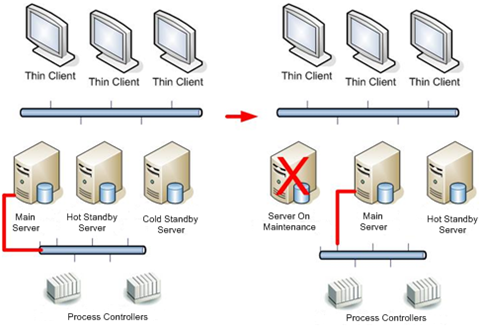
Figure 4: Example of settings with three redundant servers
However, you should notice that the MTBF of redundant servers is already high enough for most applications, since this number is calculated by the square value of each server MTBF:
Redundant Pair MTBF = (Individual MTBF)2
5) Critical data acquisition
Establishing acquisition priorities can depend a lot on the network and protocol being used. For protocols supporting an exception system, that is, protocols transmitting only data changes, the priority is already defined in the order that these changes occur. On the other hand, for protocols working with a polling system, you can define either an individual or group update rate that is lower for critical variations, causing the other variables to naturally have higher rates.
As a result of the need to get more easily manageable automation and data acquisition systems, we have seen the raise of new networks and protocols that allow a wider, more reliable interaction with plant floor devices.
For instance, in a traditional, polling-based protocol such as Modbus, the engineer or technician responsible for the system’s setup must know all Modbus memory map in the field device. Each address must be identified and typified (integer, real, text, etc.), and the same person must be responsible for defining a polling or individual scan rate, within the SCADA system itself. This happens because functionalities offered by Modbus are very limited, although widely spread and easily implemented.
But for new protocols and networks, such as IEC 61850, Fieldbus HSE, and SNMP (used for monitoring Ethernet networks), to name a few, there are new available services that, among other benefits, privileged the traffic of critical information through the model of communication by exception, including the use of unsolicited messages, where the device automatically sends the critical data without a server request.
In addition, an automatic identification methodology of the device’s databases, or Device Browsing, allows saving a lot of application development time, and also prevents typing and settings errors.
However, this does not prevent that some optimizations should be done in traditional polling protocols. A possible optimization would be grouping variables in close positions in order to create virtual communication blocks, aiming at reducing the number of requests to the devices. This reduces network traffic and allows updating more variables per time units.
6) Data updating in operation consoles
As for the operator’s graphical user interface, this can be viewed in any computer or in some systems, in wireless mobile devices like PDAs that receive graphical interfaces (screens) as well as process variables through main servers.
It is important to notice that sending information collected by the I/O drivers, after being processed by the application servers through the operator graphical interface, must occur in the most optimized way as possible, so that the delay between data arrival at the communication server and its update at the operation console happens almost instantaneously.
The solution for this type of communication is based on the concept of Publish-Subscribe. In this technique, the server has an information context, and a dedicated, by-exception communication channel for all operator consoles. The console, by opening one or more supervisory screens, makes a signature of the variables that need updating on the server.
The server, by its turn, maintains an internal list of signatures for every console that is logged in. When a variable is altered in the server, its internal processes automatically check if any console has that signed variable at the time. If positive, this notification is inserted on a notification queue that should be sent to all consoles.
Depending on a few system settings, it is possible to define whether notification queues will be sent only after reaching a certain size or a certain time limit, or then emptied instantly.
This notification system can still go through another process (cryptography and compressing), which has two purposes: preventing hackers from crashing the system and maintaining the operational security of a plant, and also reducing the size of messages and traffic time, mainly in narrow band networks.
This task, however, has the problem of demanding more machine processing (clients and servers) while compressing or decompressing, so in some cases it may slow down the response – although improving security.
7) New frontiers
Nowadays, new networks and protocols allow establishing really efficient data exchange methods, which makes today’s concerns be focused on the human factor of systems, in case critical data interpretation must be performed by a human operator. An issue that raises concerns is the increase of event messages (or alarms) for the same operator, a problem that has few solutions available on the market.
The main concern is on the fact that the great majority of DCS (Digital Controlling Systems – where SCADA and DCSD systems belong) do not have adequate tools for dealing with a huge amount of alarms. This way, system’s operators, as human beings, have a limit on message processing at each time interval. In continuous stressful situations, or even floods, the messages overload generated can make the operators disregard them.
This way, we understand that SCADA systems should provide more tools that could help operators on these moments, for example, distinguishing which actions are the most important and therefore must have an immediate response, and which ones have lower priority because they are consequences of other events.
