1) Introdução
Devido a sua flexibilidade, os sistemas SCADA (Supervisory, Control and Data Acquisition) podem ser utilizados em uma grande variedade de processos, que incluem sua aplicação como ferramenta de análise operacional, dependendo das condições desejadas, mas principalmente na aquisição de dados e monitoramento. Em geral, os sistemas SCADA são usados com eficiência quando existe um grande número de variáveis a serem coletadas em intervalos relativamente pequenos (da ordem de segundos).
Para algumas aplicações como (por exemplo) sistemas de vibração, são necessários equipamentos e softwares específicos para maior eficiência com poucas variáveis a taxas muito menores (da ordem de milissegundos). Isto não impede, entretanto, que os softwares SCADA conectem-se a qualquer tipo de sistema – inclusive sistemas de monitoramento rápidos – focando, porém, as informações em nível operacional e gerencial. Um exemplo desse caso é a coleta de perturbações em relés de proteção, conhecidos como arquivos COMTRADE. Esses arquivos contêm uma imagem de um período onde houve uma perturbação no sistema que está sendo monitorado. Apesar de possuir dados com resolução de milissegundos, é possível que um sistema SCADA capture os arquivos após a ocorrência da perturbação, para análise nos próprios consoles do sistema.
2) Arquitetura de sistemas atuais
Nos sistemas SCADA mais modernos, que trabalham com o conceito de servidores e consoles de operação, a distribuição do processamento tem arquitetura bastante flexível, podendo alocar todas as principais tarefas de monitoramento e supervisão num único computador ou separar as principais atividades em diversas unidades, com opção de redundância nativa em cada uma delas. Podemos ver um exemplo dessa arquitetura na Figura 1.
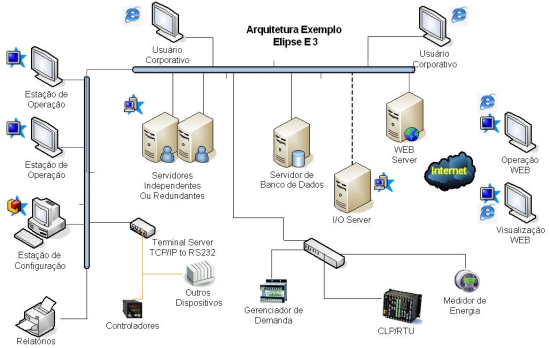
Figura 1: Exemplo de arquitetura de sistema SCADA usando o E3, da Elipse Software
A aquisição dos dados pode ocorrer através de qualquer servidor OPC ou por drivers de comunicação nativos, que permitem um bom grau de otimização na comunicação e flexibilidade de configuração, inclusive de forma online. Podem ser alocados servidores apenas para execução destes processos, que reportam as modificações nos dados para outras máquinas através de OPC ou de outros protocolos sobre TCP/IP que, trabalhando em modo de exceção, reportam os dados no padrão VQT (Valor, Qualidade e TimeStamp).
3) Por que utilizar redundância?
Quando os sistemas SCADA passaram a adotar o conceito de thin client, em contraposição a arquiteturas tradicionais rich client (onde cada estação SCADA deveria ter uma cópia não sincronizada de toda a base de dados), alguns técnicos passaram a criticar esta nova filosofia pela centralização em um único servidor as principais atividades do sistema, criando um ponto vulnerável.
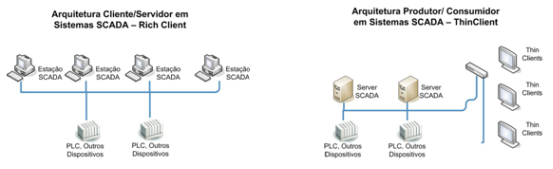
Figura 2: Arquitetura tradicional Rich Client versus arquitetura Thin Client
A resposta para esse problema foi em criar um mecanismo de redundância nativa para os servidores, de modo que, em situação de failover (troca entre os servidores), as estações clientes (ou thin clients) automaticamente redirecionassem o tráfego para o novo servidor ativo. Na arquitetura demonstrada na Figura 1, podemos ver um exemplo de redundância em servidores que fazem o trabalho de consolidação e distribuição dos dados.
A redundância em equipamentos de aquisição também é suportada. Dessa forma, os drivers de comunicação podem chavear para o próximo dispositivo disponível quando for percebida uma falha específica, e não somente quando houver erros de comunicação.
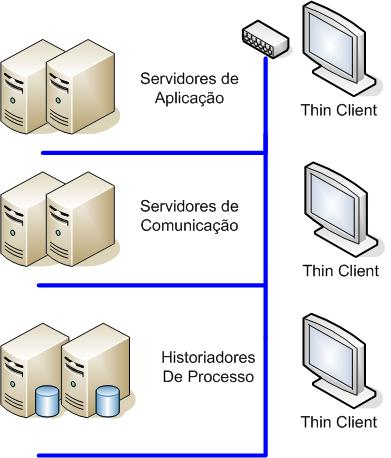
Figura 3: Distribuição de atividades em pares redundantes
Avançando um pouco mais na solução, através do uso de mecanismos de sincronização de arquivos e bases de dados, já é possível distribuir partes das tarefas de um sistema complexo em diversos servidores, com a opção de redundância em pares. Dessa forma, entretanto, ainda se mantêm os benefícios em relação à arquitetura antecessora, como o sincronismo automático das telas de processo entre todas as consoles de operação e outras facilidades de manutenção.
4) Arquitetura triplamente redundante
Para sistemas onde o principal problema não é exatamente o tamanho da aplicação, mas sim a necessidade de operação 24×7 com MTBF (Mean Time Between Failures) de muitos anos, ou seja, com alto índice de confiabilidade, alguns usuários podem preferir uma arquitetura triplamente redundante para os servidores.
Entretanto, a única razão prática para utilizar essa arquitetura em termos de servidores SCADA seria o fato de que quando houver uma falha em um servidor (e durante o tempo que esse estiver sendo reparado), a operação ficará centralizada em apenas um servidor, sendo interessante então que neste momento uma terceira máquina possa assumir a funcionalidade de reserva.
Mesmo que a possibilidade de que isto realmente venha a ocorrer seja bastante questionável, já existem soluções de mercado que permitem tal configuração. A questão é que se por algum motivo o MTTR (Mean Time To Repare) for alto, pode valer a pena manter uma máquina pronta para assumir a atividade.
Uma das arquiteturas possíveis para atender esse requisito exibe um servidor principal, um servidor standby ativo ou “quente” (com drivers de comunicação ativos ou não) e mais um terceiro servidor em standby inativo ou “frio”. Dessa forma, o caso o servidor principal fique indisponível, o servidor standby passa a ser o principal, e o servidor inativo pode manualmente ou automaticamente ser colocado em standby ativo, caso o dano verificado no primeiro servidor seja suficiente para que essa atitude seja tomada.
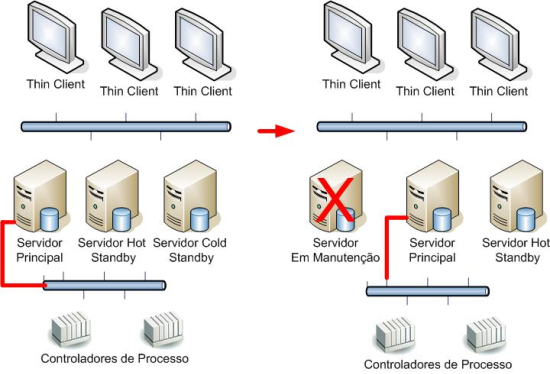
Figura 4: Exemplo de configuração com três servidores redundantes
Entretanto, vale ressaltar que o MTBF de servidores redundantes já é alto o suficiente para a grande maioria das aplicações, visto que esse número é calculado elevando-se o MTBF de cada servidor ao quadrado:
MTBF Par Redundante = (MTBF Individual)2
5) Aquisição de dados críticos
O estabelecimento de prioridades de aquisição pode depender muito da rede e do protocolo utilizados. Para protocolos que suportam um sistema de exceção, ou seja, que transmitem apenas as mudanças nos dados, a prioridade já é definida pela própria ordem em que as modificações ocorrem. Já para os protocolos que trabalham em sistema de polling, pode-se definir uma taxa de atualização individual ou de grupo mais baixa para as variáveis mais críticas, fazendo com que as demais variáveis passem naturalmente a ter taxas um pouco mais altas.
Como resultado da necessidade de se obter mais facilidade na administração de sistemas de automação e aquisição de dados, temos visto o surgimento de novas redes e protocolos que permitem uma interação muito mais abrangente e confiável com os dispositivos de chão de fábrica.
Para se ter uma idéia, em um protocolo tradicional e baseado em polling como o Modbus, é necessário que o engenheiro ou técnico responsável pela configuração do sistema conheça todo o mapa de memória Modbus no equipamento de campo. Cada endereço deve ser identificado, tipado (ou seja, informar se é um número inteiro, real, texto, etc.) e ainda fica por conta da mesma pessoa definir uma taxa de polling ou scan individual, de grupo ou geral, isso tudo no próprio sistema SCADA. Isto porque as funcionalidades oferecidas pelo Modbus são bastante limitadas, apesar de bastante difundidas e de simples implementação.
Já em novos protocolos e redes, como o IEC 61850, Fieldbus HSE e SNMP (utilizado para monitoração de redes Ethernet), apenas para citar alguns exemplos, estão disponíveis novos serviços que, entre outros benefícios, privilegiam o tráfego de informações críticas pelo modelo de comunicação por exceção, inclusive pelo uso de mensagens não solicitadas, onde o equipamento envia automaticamente os dados mais críticos sem uma solicitação do servidor.
Além disso, uma metodologia para identificação automática da base de dados dos equipamentos, ou Device Browsing, permite poupar um tempo enorme no desenvolvimento dos aplicativos, além de diminuir o aparecimento de erros de digitação ou configuração.
Isso não impede, entretanto, que algumas otimizações possam ser feitas em protocolos de polling tradicionais. Uma otimização possível seria o agrupamento de variáveis em posições próximas, de modo a criar blocos virtuais de comunicação, com o objetivo de diminuir o número de requisições aos equipamentos. Isso faz com que se ocupe menos a rede, permitindo atualizar um maior número de variáveis por unidade de tempo.
6) Atualização dos dados nos consoles de operação
Quanto à interface gráfica do operador, essa pode ser visualizada em qualquer computador ou em alguns sistemas, em dispositivos móveis sem fio tipo PDA, que recebem tanto as interfaces gráficas (telas) quanto as variáveis de processo através dos servidores principais.
Importante observar que o envio das informações coletadas pelos drivers de comunicação, depois de processadas pelos servidores de aplicação até chegarem à interface gráfica do operador, deve ocorrer da maneira mais otimizada possível, para que o atraso entre a chegada do dado no servidor de comunicação e sua atualização na tela do console de operação ocorra de forma praticamente instantânea.
A solução encontrada para esta comunicação baseia-se no conceito Publish-Subscribe. Nesta técnica, o servidor possui um contexto de informações e um canal de comunicação dedicado e por exceção para cada console do operador. O console, ao abrir uma ou mais telas de supervisão, faz uma assinatura das variáveis que precisa ter atualizadas no servidor.
O servidor, por sua vez, mantém uma lista de assinaturas internamente para cada console que está logado. Quando uma variável sofre uma alteração no servidor, automaticamente os seus processos internos verificam se algum console possui aquela variável assinada atualmente. Caso positivo, essa notificação é inserida numa fila de notificações que deve ser enviada para cada console.
Dependendo de algumas configurações no sistema, é possível definir que as filas de notificações sejam enviadas somente após terem atingido um certo tamanho ou tempo máximo, ou então que sejam esvaziadas instantaneamente.
Este sistema de notificações pode ainda passar por mais um processo (criptografia e compactação) que possui finalidade dupla: não apenas ele dificulta a ação de hackers e mantém a segurança operacional de uma planta, como também diminui o tamanho das mensagens e o tempo de tráfego, principalmente em redes de menor banda.
Em contrapartida, esta tarefa exige mais processamento das máquinas (tanto clientes como servidores) no processo de compactação ou descompactação, por isso em alguns casos pode até tornar mais lenta a resposta – porém oferecendo maior segurança.
7) Novas fronteiras
Atualmente, as novas redes e protocolos permitem estabelecer métodos de troca de dados bastante eficientes, o que faz com que as preocupações atuais estejam voltadas para o fator humano no sistema, caso seja necessário que a interpretação do dado crítico seja feita por um operador humano. Um problema que desperta muita atenção é o acúmulo de mensagens de eventos (ou alarmes) para o mesmo operador, problema esse que encontra poucas soluções disponíveis no mercado.
A principal questão está no fato de que a grande maioria dos SDC (Sistemas Digitais de Controle – onde se encontram os sistemas SCADA e SDCDs) não possuem ferramentas adequadas para o tratamento de grande quantidade de alarmes. Dessa forma, os operadores de sistemas, como seres humanos, possuem um limite de processamento de mensagens a cada intervalo de tempo. Em situações de estresse contínuo ou mesmo de avalanches, o excesso de mensagens geradas pode fazer com que os operadores passem a desprezá-las.
Nesse contexto, entendemos que os softwares SCADA deveriam fornecer mais ferramentas que pudessem auxiliar os operadores nesses momentos, como por exemplo, distinguindo quais são as ações mais importantes e devem ter uma resposta mais imediata, e quais têm prioridade mais baixa, por serem apenas consequência de outros eventos.
