1) INTRODUÇÃO
A constante necessidade de aperfeiçoamento dos processos produtivos, incluindo pressões por menores custos e prazos, requer que se tenha cada vez mais informação e conhecimento sobre tudo o que ocorre em uma planta industrial.
Neste contexto, é crescente a necessidade de sistemas que concentrem em Bancos de Dados Históricos os dados coletados de diversas fontes heterogêneas de informação, como Sistemas SCADA e PLCs de diversos fabricantes diferentes, de forma a criar um repositório central que permita desenvolver inteligência sobre o processo.
Tais sistemas, conhecidos como Historiadores de Processo ou PIMS (Plant Information Management Systems), permitem transformar dados brutos em inteligência do processo através de:
- Eliminação de ilhas de informação.
- Integração de sistemas como ERP e Supply-Chain, entre outros, com o chão-de-fábrica.
- Realização de cálculos sobre os dados coletados.
- Disseminação das informações para os colaboradores da empresa, que assim podem, entre outros, obter indicadores de performance ou eficiência, comparar lotes de produção, visualizar sinóticos de várias partes da planta simultaneamente, etc.
Os softwares PIMS permitem guardar dados analógicos, digitais e textos (strings), além de outros tipos de dados como imagens e sons. O grande volume desses dados, aliado à necessidade de armazenamento por períodos longos (cinco anos ou mais) e de obter consultas rapidamente, representam um grande desafio para os softwares historiadores.
Para reproduzir com maior exatidão os dados originais, bem como para proporcionar uma boa velocidade de descompressão dos dados, os softwares PIMS apresentam o conceito de “Banco de Dados Temporal”. Isso significa que para cada amostra coletada, devem ser processados seu valor, timestamp (instante da coleta) e qualidade, que indica a confiabilidade do dado. Dessa forma, o banco de dados é criado internamente de forma a facilitar a busca de uma sequência de valores da mesma variável.
2) TECNOLOGIA DE BANCO DE DADOS PROPRIETÁRIA
Alguns fabricantes de softwares historiadores, mediante a necessidade de performance exposta acima, optaram por desenvolver sua própria tecnologia de banco de dados. Isto significa que somente esse fabricante detém o conhecimento de como o armazenamento efetivamente funciona, sob o benefício de (pelo menos em teoria) obter velocidades de acesso mais altas devido à ausência de overheads das camadas de abstração de bancos de dados.
Um exemplo de banco de dados proprietário pode ser visto abaixo, onde são exibidos filesets que correspondem a certos períodos de dados. Geralmente existe o fileset “ativo”, onde são inseridos os dados atuais, e os filesets de períodos anteriores, que podem estar disponíveis (montados) ou indisponíveis (desmontados) para consulta. Estes últimos servem para o armazenamento de longo prazo.
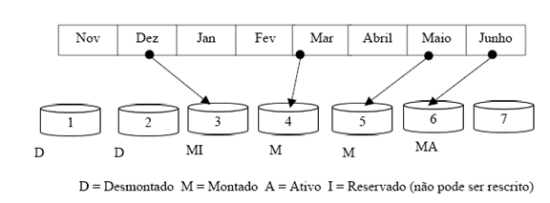
Figura 1: Organização de filesets em software PIMS
Dentro de cada fileset são armazenados os registros de cada variável no sistema temporal, ou seja, são agrupadas várias coletas de uma mesma variável em sequência, de forma comprimida.
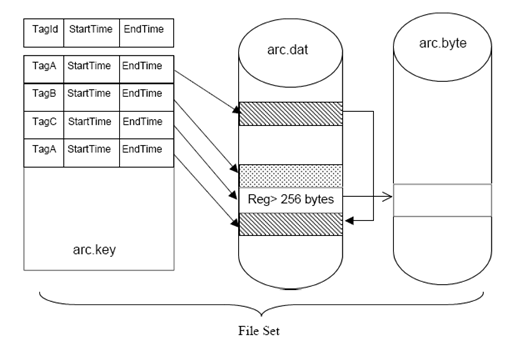
Figura 2: Organização interna de um fileset em software PIMS
Para poder fornecer dados a outros sistemas, os historiadores disponibilizam interfaces de acesso. Uma destas interfaces é a do padrão OLE DB, usado por programas Windows para acessar um banco de dados de forma relacional, que é o método tradicional de acesso a Banco de Dados. Este padrão permite utilizar as operações de SELECT e UPDATE, por exemplo.
Entretanto, mesmo com a interface OLE DB, o núcleo do Historiador (PIMS) ainda participa da transação, ou seja, mesmo depois de consultados no banco proprietário, os dados ainda serão manipulados pelo núcleo, pois estes precisam ser descomprimidos ou manipulados a fim de serem entregues para a interface OLE DB. Esta arquitetura pode ser vista abaixo.
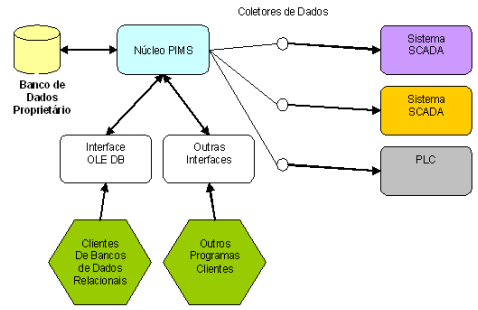
Figura 3: Arquitetura tradicional de sistemas PIMS
3) TECNOLOGIA DE BANCO DE DADOS NÃO-PROPRIETÁRIA
Outros fabricantes de sistemas PIMS optam por utilizar um banco de dados comercial para armazenamento dos dados, tipicamente o Microsoft SQL Server®. Apesar do SQL Server (assim como a maioria dos bancos de dados comerciais) oferecer uma organização interna bem conhecida (bancos, tabelas, Stored Procedures, etc.), a necessidade de performance levou à criação de estruturas temporais bastante complexas nas tabelas.
A compressão das informações de valor + timestamp + qualidade de cada amostra tornam o acesso direto ao banco de dados SQL de um PIMS uma tarefa tão impossível quanto no primeiro caso. Isso significa que, para que um software cliente acesse os dados historiados sob a forma de consultas SQL, é necessário passar, da mesma forma que no modelo anterior, por uma interface OLE DB, que ainda conta com o núcleo PIMS para a descompressão ou transformação dos dados.
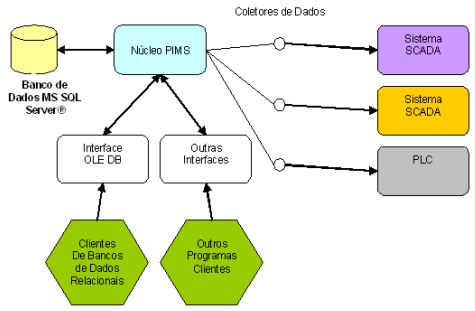
Figura 4: Arquitetura de sistemas PIMS baseada em banco de dados MS SQL Server
4) ABORDAGEM DESENVOLVIDA
Neste artigo, adaptamos a tecnologia não proprietária (utilizando bancos de dados comerciais) baseado na premissa de que o formato que os dados armazenados é de conhecimento público e de fácil acesso. Isto significa que qualquer programa, desde que devidamente autorizado pelo administrador, é capaz de acessar diretamente a base de dados temporal/relacional e extrair a informação desejada, sem o auxílio do núcleo PIMS ou de uma interface OLE DB específica.
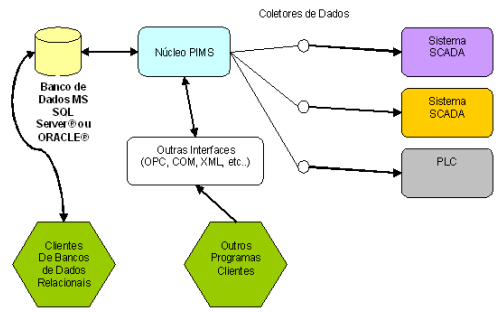
Figura 5: Nova arquitetura PIMS desenvolvida
Ainda existe uma maior liberdade de acesso às informações armazenadas, visto que não são necessárias cópias extras de acesso do núcleo PIMS, já que cada cliente acessa o banco de dados diretamente (Microsoft SQL Server® ou Oracle®).
5) ESTRUTURA DE TABELAS
A metodologia utilizada para o armazenamento dos dados é baseada na definição de módulos de armazenamento, chamados de Storage. Cada Storage permite definir um conjunto de variáveis para armazenamento, que podem ser analógicas, digitais ou texto (simultaneamente). Além disso, cada um possui um nome base de tabela, que será usada para o armazenamento dos dados após serem processados pelo algoritmo de compressão.
Entretanto, para manter um compromisso entre a facilidade de acesso pelos clientes externos e a manutenção de uma boa performance de gravação e recuperação dos dados, foi criado para cada Storage um sistema de tabelas principais e de backup.
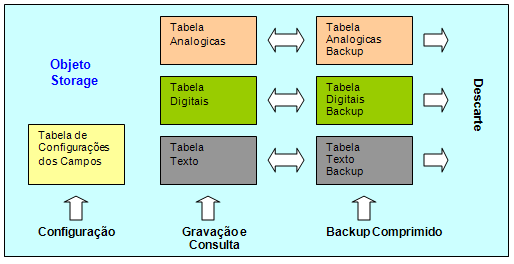
Figura 6: Estrutura de tabelas Storage
A tabela principal, que contém um período de dados definido pelo usuário, é onde os dados recentemente coletados estão sendo inseridos. Ela também permite consultas tanto pelo núcleo PIMS como por outros softwares clientes. Os dados nestas tabelas estão dispostos em um formato híbrido entre os modos Relacional e Temporal, porém não são comprimidos. Cada registro tem o seguinte formato:
Por sua vez, a tabela backup contém os dados que foram descartados pela tabela principal, dentro de um período máximo também definido pelo usuário. Entretanto, o formato da tabela backup não é o mesmo da tabela principal, já que para economizar espaço em disco, os dados aqui armazenados estão realmente em um formato temporal e comprimido, enquanto que na tabela principal eles estão dispostos em um formato pseudo-temporal e não comprimido.
Na arquitetura desenvolvida, somente o núcleo PIMS é capaz de acessar as tabelas de backup, seja compactando os dados das tabelas principais que excederem o período máximo desejado, seja descompactando um período mais antigo do backup (solicitado por algum usuário) e reinserindo esses dados temporariamente na tabela principal.
A verificação da transferência de dados excedentes da tabela principal para a de backup, assim como o descarte da tabela de backup, ocorre a intervalos definidos pelo usuário (por exemplo, a cada 24 horas).
A tabela de configuração de campos, é onde são guardadas as configurações de cada campo. A principal característica dessa tabela é associar um índice único para cada variável armazenada, que será utilizado nas tabelas principal e de backup para sua identificação.
6) ALGORITMOS DE COMPRESSÃO
A necessidade de gravação de cada ponto será verificada conforme o núcleo PIMS for recebendo os valores que estão sendo coletados. Isso acontece porque se variável não muda (ou muda pouco) a cada período de tempo, será apenas necessário armazenar sua mudança ou taxa de variação, e não todos os dados repetidos, o que poluiria o banco.
Dessa forma, para cada variável que se deseja armazenar, é necessário definir um tipo (analógico, digital ou texto); para as variáveis analógicas, também é preciso definir um valor de banda morta (em porcentagem ou em valores absolutos) e os tempos mínimo e máximo de gravação.
Neste caso, foi utilizado o algoritmo BoxCar/BackSlope para definir a necessidade de gravação de cada ponto.
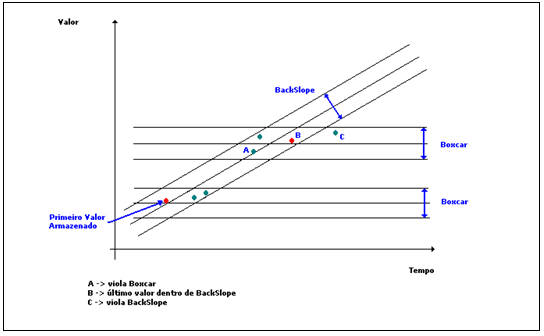
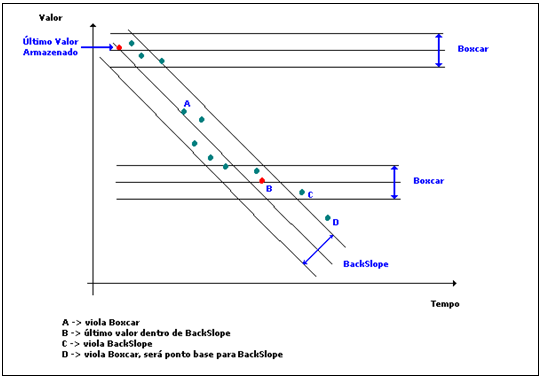
Figura 7: Algoritmo BoxCar/BackSlope
A partir da banda morta informada, o algoritmo estabelece um limite de variação horizontal em relação ao último ponto armazenado (BoxCar). A cada novo ponto reportado, são calculados limites de variação diagonais, utilizando a mesma banda morta (BackSlope).
Em linhas gerais, quando um ponto violar as duas áreas imaginárias definidas pelas linhas BoxCar e BackSlope, o ponto deve ser armazenado.
Exceções para a regra acima ocorrem quando há uma mudança na qualidade do ponto, ou quando o tempo máximo desde a última gravação for ultrapassado – nessas circunstâncias, o ponto é sempre gravado.
7) CONSULTAS ÀS TABELAS DE DADOS
Embora o formato dos dados na tabela principal seja bastante simples, o processo de consulta de forma direta pode ser um processo relativamente trabalhoso:
- Dada uma variável do sistema, é necessário obter qual índice será associado à variável.
- Dado um intervalo inicial e final, é necessário selecionar os registros cujo índice seja igual ao obtido anteriormente, definindo também se devemos incluir somente registros com qualidade BOA ou qualquer registro encontrado.
Para facilitar esse processo, e para permitir manipulações básicas nos dados, foram disponibilizadas algumas Stored Procedures que podem ser chamadas diretamente, o que elimina o trabalho acima. São elas:
- Último valor
- Valor arquivado em relação a uma data/hora
- Atributo de tag
- Valores armazenados a partir de uma data/hora
- Valores armazenados num intervalo de datas
- Valores amostrados/interpolados num intervalo de datas
- Valores calculados num intervalo de datas (máximos, mínimos, médias, desvios, etc.)
8) EXEMPLO DE ACESSO VIA PLANILHAS ELETRÔNICAS
Abaixo, vemos um exemplo de acesso aos dados do PIMS via Microsoft Excel. Foi construída uma macro que permite conectar-se ao banco de dados diretamente, disponibilizando as consolidações de dados das Stored Procedures.
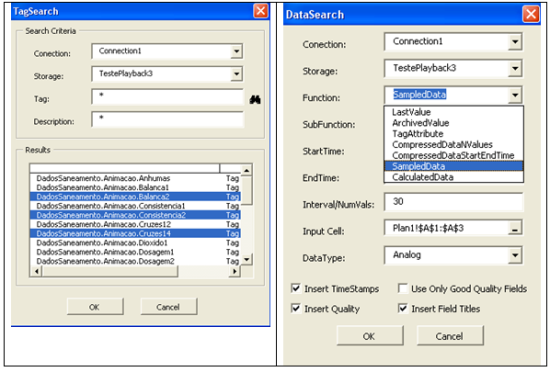
Figura 8: Macros do Excel para acesso aos dados de PIMS
9) CONSIDERAÇÕES FINAIS
Este artigo ilustra como o desenvolvimento de um sistema PIMS, cujas informações podem ser acessadas de forma mais democrática e livre por vários softwares clientes, permite aumentar o número de possibilidades de integração. A própria escolha do banco de dados pode ser feita entre os dois principais fornecedores do mercado. Além disso, verificamos que o algoritmo escolhido (BoxCar/BackSlope) permite reduzir em aproximadamente 90% o tamanho do banco de dados quando comparado aos históricos relacionais convencionais.
O próprio formato utilizado (temporal) permite que várias consolidações, cálculos e até mesmo aplicações sejam desenvolvidas com base nos dados armazenados, servindo como base para a implementação de diversos sistemas de inteligência operacional.
