Qual a relação entre Data Historians (PIMS), Data Lakes e Data Hubs no contexto da Industria 4.0 e Transformação Digital Industrial (IX)? Para que servem e como podemos utilizá-los da melhor forma?

Quais as tecnologias disponíveis para a gestão de dados na Transformação Digital Industrial (IX) da minha empresa? Qual o papel de cada sistema?
Estas perguntas são recorrentes quando falamos sobre o valor e o potencial uso dos dados industriais. Uma simples busca na internet por gestão de Big Data é o suficiente para retornar um grande número de ofertas e soluções. Isso pode nos causar uma certa confusão: afinal, quais são os tipos de tecnologias de dados existentes? Qual o papel que cada sistema pode desempenhar, dentro de um contexto de Transformação Digital, mais especificamente dentro do ambiente industrial?
Este artigo não tem por objetivo, de forma alguma, esgotar este assunto. Pretendemos, no entanto, jogar uma luz sobre as principais tecnologias e como podemos aproveitar o que cada uma oferece de melhor. Além disso, propomos arquiteturas que promovem o melhor uso possível desses dados.
Mas antes, é importante fazer uma pequena revisão sobre as tecnologias de armazenamento de dados e sistemas relacionados. Dessa forma, conseguiremos compreender melhor o papel de cada um.
Bancos de Dados
A história dos bancos de dados se confunde com os primórdios da história da evolução da própria computacão: há registros de bancos de dados em funcionamento ainda na década de 1960. Hoje, são duas as principais tecnologias de bancos de dados: bancos baseados no padrão SQL, como o PostgreSQL, MySQL e Microsoft SQL Server, e bancos baseados no padrão No-SQL, como o MongoDB ou Apache Cassandra.
Continuamos utilizando bancos de dados hoje em dia pelos mesmos motivos que os utilizávamos nos anos 60: para escrever e ler dados diversas vezes. Para isso, utilizamos as operações CRUD (Create, Read, Update, Delete) e transações ACID (quando suportadas), dadas as restrições do teorema CAP – onde, em um sistema de armazenamento distribuído, uma vez que é necessário o particionamento (P), o sistema deve sempre escolher entre disponibilidade (A) e consistência (C).
Cada banco de dados possui suas particularidades, inclusive a maneira como se propõe a resolver estes problemas. Mas, de forma geral, eles estão aqui para ficar – por pelo menos uma boa e importante razão: são capazes de atualizar registros de uma forma eficiente e, também, de forma consistente e/ou disponível.
Séries Temporais
Posteriormente, a necessidade de armazenar e processar dados de sensores, estados, sinais e variáveis advindas dos processos industriais com base no instante de sua geração impulsionou a criação de uma categoria específica de banco de dados. São os chamados bancos de dados de “séries temporais”; é possível implementar este conceito tanto em bancos SQL quanto em No-SQL.
O principal índice de consultas de um banco de dados temporal é o horário (Timestamp). Isso otimiza a velocidade de resposta com base em um instante específico ou intervalo de datas.
Entretanto, um Banco de Dados de séries temporais sozinho não resolve todos os problemas de processamento de dados em um ambiente industrial. É necessário coletar, processar, exibir, alertar, controlar, além de armazenar e consultar as informações, dentre outras funções.
SCADA e PIMS
Concomitantemente à história dos bancos de dados, ocorria a adoção dos sistemas SCADA pela indústria. A utilização de computadores neste ambiente ocorria em diferentes frentes, com diferentes necessidades.
O SCADA permitia a comunicação com sensores e CLPs, realizava o monitoramento de alarmes/eventos e armazenamento básico de dados (alguns em arquivos proprietários ou bancos SQL), mas estava (e ainda está) voltado, principalmente, à operação das plantas.
A necessidade de analisar os dados coletados com maior profundidade para a obtenção de indicadores e auxílio no planejamento deu origem ao Historiadores de Dados Industriais ou PIMS (Plant Information Management System). Por definição, os PIMS possuem um engine de séries temporais em seu núcleo, mas também realizam diversas outras funções. Dentre elas, estão a contextualização da informação, controle de permissões sobre os dados, execução de cálculos e exibição dos dados em diferentes formatos e para diferentes perfis de colaboradores, sem as restrições operacionais associadas ao SCADA.
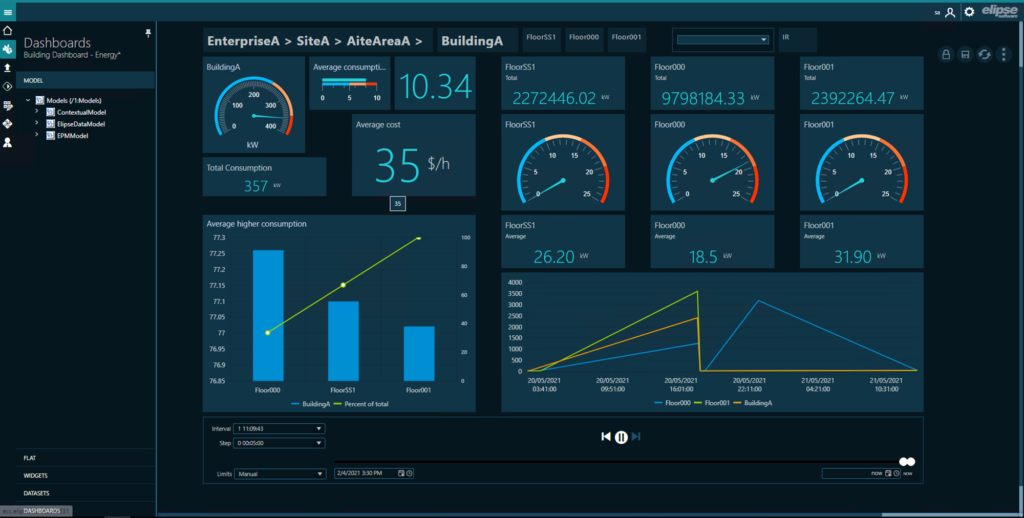
Nos dias de hoje, os Historiadores continuam desempenhando um papel extremamente relevante na organização dos dados operacionais na indústria. Em especial, ao tornar estes dados acessíveis pelo padrão OPC UA, eles permitem que diversos sistemas e atores possam colaborar de forma consistente e organizada.
Desafios da Transformação Industrial (IX)
O cenário atual se caracteriza pela necessidade de redução de custos, integração dos diversos níveis hierárquicos, rapidez na inovação e maior customização. Para isso, precisamos utilizar dados de diversas fontes como insumo, a fim de buscar as melhores alternativas no contexto de cada departamento e processo.
Comparamos o custo e disponibilidade das tecnologias versus os benefícios e ganhos decorrentes das ações implementadas com base em análises sobre os dados. Dessa forma, concluímos que o desafio de coletar, organizar e processar dados e transformá-los em informação prática pode valer muito a pena. Isso porque hoje é possível processar bilhões de registros com recursos computacionais pagos proporcionalmente pelo uso e, com base nas informações obtidas, realizar ações que podem render lucros ou reduções de custos muito superiores.
Isto não significa, entretanto, que maior quantidade de dados é sinônimo de maior qualidade nos resultados. Não se trata disso; discutiremos este assunto em um próximo artigo.
Outra discussão que cabe neste momento é sobre dados: quais deles podemos (ou devemos) processar localmente (edge computing), dentro da empresa, e quais deles devemos levar para a nuvem (hybrid e/ou cloud computing), considerando os aspectos de velocidade, abrangência, custos e segurança da informação.
Mesclando Dados
Eis que para atender as demandas da Transformação Digital, precisamos unir diversos tipos de dados, com diferentes contextos e natureza, para diferentes perfis de colaboradores.
Dentro do ambiente industrial, podemos ter esses dados sob a forma de séries temporais, ou ainda tabelas relacionais (SQL), bancos No-SQL, arquivos (Logs, JSON, XML), informações estruturadas ou não estruturadas. E quais são os caminhos ou formas para gerir estes dados?
Bem, um caminho mais tradicional seria escalar o Banco de Dados. Eles podem, de fato, crescer em tamanho individual (scale-up) e também serem distribuídos (scale-out), mas a um custo alto. Isto está relacionado ao fato de que o poder de processamento e de armazenamento estão intimamente ligados entre si em um Banco de Dados.
De forma geral, um banco de dados tem o propósito de armazenar, atualizar e deletar dados “quentes”, de forma a otimizar o armazenamento, recuperação e atualização, em troca de uma complexidade adicional e custo computacional.
Mas, e quando falamos da necessidade de processar dezenas ou centenas de terabytes, quais são as opções?
Data Warehouse
Em um passado não tão distante, quando uma grande quantidade de dados necessitavam passar por análises, a tecnologia mais usual baseava-se na criação de um grande repositório local. Este repositório permitia a ingestão de dados de diferentes sistemas via scripts ETL (Extract, Transform, Load). Após um extenso trabalho de consultoria por parte de especialistas, estes scripts eram capaz de produzir relatórios para a alta gerência. Além de custoso, este sistema trabalhava com dados que ficavam rapidamente obsoletos, dada a necessidade das empresas de agir cada vez mais no tempo real.
Hadoop e HDFS
O Hadoop surgiu em 2005 como uma alternativa open-source ao Data Warehouse. Basicamente, ao invés de storages e servidores proprietários com chips de alto desempenho, o Hadoop propunha o uso de diversos computadores comuns em paralelo, utilizando a tecnologia Map-Reduce e o armazenamento dos dados de forma distribuída e escalável via HDFS (Hadoop Distributed File System). Os dados não eram tão fáceis de consultar quanto as consultas preparadas em ETL do Data Warehouse, mas era possível obter resultados similares a um custo muito mais baixo.
Hoje em dia ainda existem muitas soluções de Big Data baseadas em Hadoop (por exemplo: Cloudera, HortonWorks e IBM). No entanto, a manutenção de um ambiente Hadoop também é complexa e custosa, dada a variedade de componentes e administração do cluster.
Outro ponto a considerar é que o Hadoop não é compatível com a arquitetura Kubernetes (Containers). Isso, em si só, não é um grande problema. Porém, é importante notar que o uso de containers é a tecnologia de computação mais escalável atualmente: ao dividir um grande sistema em componentes menores (micro serviços), cada um executado em um container, podemos construir e testar um grande sistema em miniatura, semelhantemente a um ambiente de produção. A chave aqui está na simplicidade, flexibilidade e redução de custos.
Data Lake
O avanço da computação em nuvem trouxe mais uma tecnologia para modificar esse panorama: o Object Storage. Este serviço está disponível em todos principais players de nuvem com diferentes nomes (ex: Amazon S3, Azure Blob Storage, Google Cloud Storage). Basicamente, ele consiste em uma REST API onde você escreve e lê dados quaisquer a partir de uma chave. Qualquer outra lógica sobre os dados deve ser realizada por uma aplicação.
Estes serviços são serverless (isto é, não é necessário contratar um servidor ou instância de VM), e são extremamente confiáveis e duráveis. Porém, com eles não há um intervalo garantido para consistência local ou entre diferentes regiões, e por isso são baratos, em comparação à um banco de dados tradicional.
Este cenário (dados armazenados livremente a baixo custo, mass sem um formato pré-estabelecido) foi chamado por James Dixon em 2010 de Data Lake.
“Então, isso quer dizer que o Data Lake nada mais é do que um repositório na nuvem?” Sim. “Mas e se eu quiser usar isso localmente?” Nestes casos, é possível utilizar, por exemplo, o Ceph.io ou o Min.io, que proveem o mesmo tipo de serviço tanto na nuvem como localmente.
Formato de Arquivos no Data Lake
Existem formatos, ao contrário de arquivos de texto simples como o XML ou o JSON, que podem melhorar o armazenamento de dados no Data Lake. Esses formatos podem conter metadados que ajudam na interpretação da informação, além de aumentar bastante a sua velocidade do processamento.
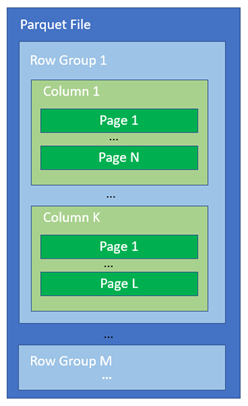
Um desses formatos é o Parquet. Introduzido em 2013, ele é orientado a colunas, contendo funcionalidades nativas para compressão de dados. É possível consultá-lo diretamente pela maioria das plataformas de Big Data, incluindo linguagens de programação como C++, C# e Python.
Data Lakehouse
Um Data Lakehouse nada mais é do que um Data Warehouse construído sobre um Data Lake. Desse modo, é possível armazenar os dados como um Data Lake, mas consultá-los como um SQL.
Uma das formas de se fazer isso é utilizar um banco de dados relacional para armazenar os metadados, isto é, a descrição dos dados (como nome de colunas etc.), bem como o nome da chave onde o arquivo com os dados pode ser obtido no Data Lake. É necessário também utilizar algum engine SQL que seja capaz de fazer o parse da sintaxe SQL e distribuir o pedido entre os diferentes nodos, e também obter os dados no Data Lake.
Esta abordagem é indicada quando a preocupação principal é a performance, ou seja, quando os dados não precisam ser alterados. Porém, esta opção é bastante trabalhosa (para não dizer não suportada) na situação oposta.
Alguns exemplos de engines e soluções que se propõe a esta tarefa são o Trino (ex-Presto SQL), Dremio e Snowflake.
Data Hub
Nas seções anteriores, vimos que um Data Lake funciona como um grande repositório, com dados para toda a organização. Ele permite armazenar dados de forma simples e fácil, embora não seja exatamente acessível para a realização de consultas.
De acordo com Hossein Rahnama, professor do MIT, uma das maiores dificuldades na implementação de um Data Lake está na criação de uma camada interativa sobre os dados, de forma que os usuários que não possuem o conhecimento de TI possam obter e gerar novos significados. E neste ponto, os Data Lakehouses podem ser uma parte da solução, a depender do tipo de utilização.
Porém, quando lidamos com dados industriais, em especial dados mais próximos do tempo real, o conceito de Data Hub pode ser o mais indicado.
O Data Hub é um repositório central em formato estrela (hub-and-spoke) onde os dados são coletados e reindexados em um novo sistema. Isto permite que se tenha dados muito mais estruturados, de forma que diversos tipos de usuários podem acessar a informação de que precisam mais rapidamente que em um Data Lake.

Data Hubs são geralmente criados por um esforço conjunto entre diferentes áreas, sendo que cada braço dessa estrutura pode ter o acesso controlado a uma parte dos dados. Note porém que um Data Hub pode ou não utilizar um Data Lake, dependendo da arquitetura e do uso desejado.
Modelagem e Contextualização
Dentro do ambiente industrial, precisamos trabalhar com dados de diversos tipos: estruturados, não estruturados e semi-estruturados, com as séries temporais se enquadrando nesta última. Além disso, dados industriais podem conter ruídos, múltiplas dimensionalidades e outros problemas que podem tornar a extração de valor bastante desafiadora.
A maneira com que podemos adicionar e manter o valor ao longo do tempo para estes dados está na aplicação de modelagens e contextualização.
Na ciência da computação, contextualização é o processo de identificar dados relevantes para uma entidade (i.e., uma pessoa, objeto, local ou processo) baseada na informação contextual da entidade, de forma que outras aplicações possam consumi-los.
Por que os Historiadores não podem ser Data Hubs?
A resposta é porque muitos dados de interesse para a Transformação Digital podem não estar no historiador, mas presentes em vários outros sistemas, como ERP, MES e GIS, dentre outros. Além disto, o Historiador não possui ferramentas nativas suficientes, com performance e escalabilidade, para modelar todos estes dados. Porém, essa tarefa pode ser realizada em conjunto com um Data Hub, de forma a explorar o melhor potencial de cada ferramenta.
De acordo com artigo publicado no blog da empresa LNS Research, um Data Hub industrial deve possuir seis funcionalidades básicas, que são o Processamento, Condicionamento, Sincronização, Contextualização, Persistência e Acessibilidade. Isso significa prover acesso aos consumidores no formato que eles necessitam – inclusive suportando um fluxo bi-direcional entre os clientes, o Data Hub e os sistemas de origem.
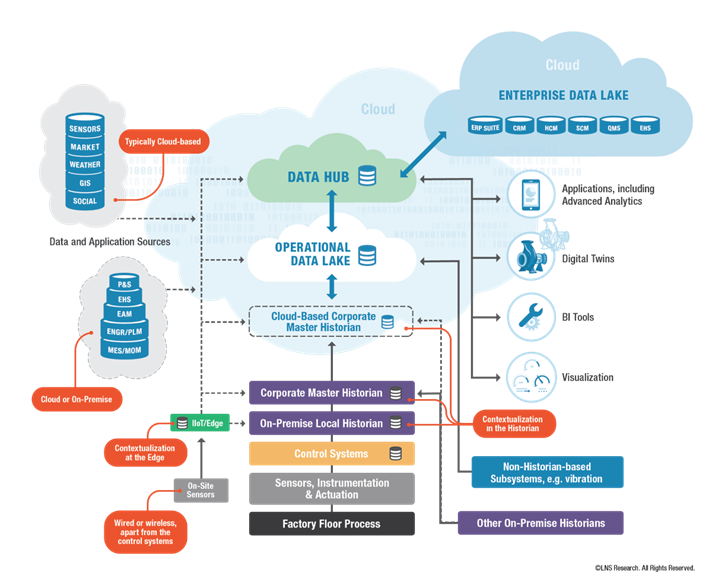
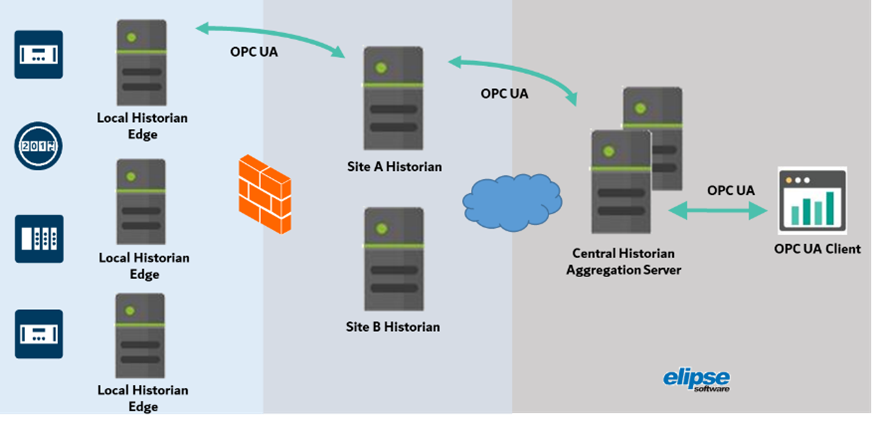
Várias destas funções estão presentes em Historiadores que, conforme podemos ver no diagrama conceitual a seguir, ocupam um lugar central na arquitetura.
Este diagrama propõe a criação de um “Data Lake Operacional” que alimenta o Data Hub a partir de dados de um Historiador Master, bem como de outros possíveis sistemas. Da mesma forma, o Data Hub também pode obter dados de outros Data Lakes corporativos.
O Data Hub na prática
Não existe uma forma única de se obter um Data Hub. É possível desenvolvê-lo internamente, a partir de componentes open-source e serviços dos provedores de nuvem. Também é possível desenvolvê-lo adquirindo ferramentas de mercado; no entanto, grande parte delas ainda estão em seus estágios iniciais e pouco adaptadas às necessidades do ambiente industrial.
Aqui na Elipse Software, acreditamos que o historiador pode auxiliar, e muito, na criação de um Data Hub. Ao introduzir conceitos de DataOps (metodologia ágil para a entrega de informação de qualidade), é possível prover, por exemplo, as seguintes funcionalidades:
- Informar modelo e contexto dos ativos, como bombas, motores e válvulas, tanto através do OPC UA, REST APIs quanto de consultas SQL (ODBC e OLE DB), que podem ser usados como metadados para outros usuários no Data Hub.
- Informar dados mais próximos ao tempo real diretamente da sua memória ou snapshot de curto prazo. Isso é importante principalmente porque estes dados podem chegar fora de ordem, dependendo da forma de aquisição, ou caso ainda estejam sendo processados e calculados.
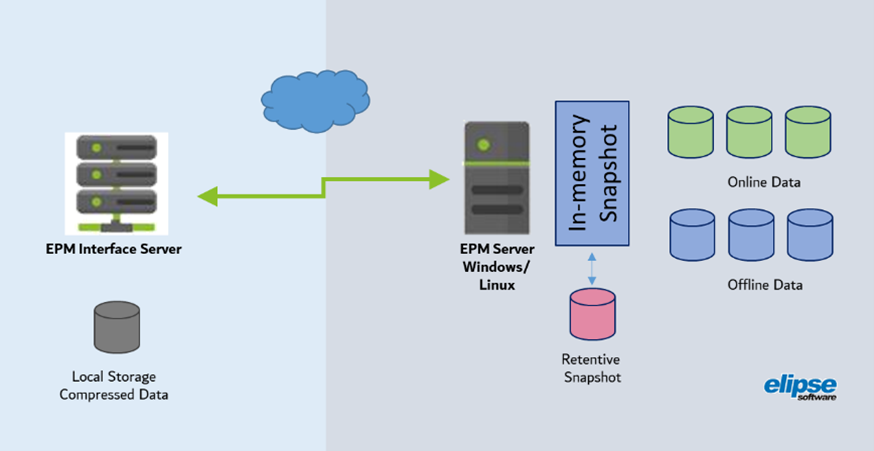
- Exportar dados já consolidados para formatos compactados (exemplo: Parquet) para um Data Lake.
- Distribuir o processamento em diversos servidores, através de recursos de agregação do OPC UA, permitindo a escolha do processamento local (Edge), Central ou na Nuvem.
- Visualizar informações do Data Hub de forma conjunta com dados próprios, realizar novos cálculos e integrá-los ao processo produtivo, via comunicação direta com sistemas SCADA e MES.
Exemplo
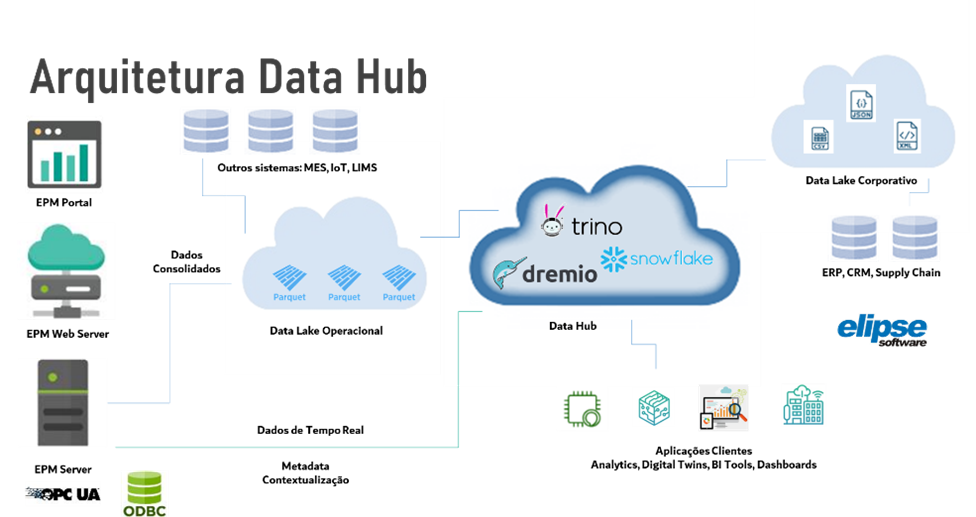
Na arquitetura a seguir, vemos um exemplo da utilização do nosso historiador, Elipse Plant Manager (EPM), de forma integrada com um Data Hub, usando como exemplo as ferramentas já citadas como o Trino, Dremio e Snowflake.
Dentre as funcionalidades dessas ferramentas, estão:
- A capacidade de manter um dicionário de metadados sobre o Data Lake.
- Processar solicitações de clientes de diversas formas, inclusive via SQL, organizando e distribuindo a tarefa de consulta entre um ou mais nodos paralelamente, e também mantendo porções dos dados em memória e realizando leitura prévia (read-ahead).
Para maiores informações sobre como utilizar o EPM em aplicações de Transformação Digital e Data Hubs, entre em contato conosco – epm@elipse.com.br
