Introdução
O Apache Parquet é um formato de arquivo binário que permite o armazenamento de dados utilizando tipos específicos, como: BOOLEAN, INT32, INT64, INT96, FLOAT, DOUBLE e BYTE_ARRAY.
Os metadados no Parquet, incluindo esquema e estrutura, são incorporados individualmente em cada arquivo, tornando o Apache Parquet um formato de arquivo autodescritivo.
O Parquet possui uma organização interna dos dados semelhante à de uma tabela de um RDBMS (Relational Database Management System, ou Sistema de Gerenciamento de Banco de Dados Relacional), com linhas e colunas. Entretanto, ao contrário dessas tabelas, os dados no Parquet são armazenados em formato colunar (um ao lado do outro).
Devido à sua estrutura colunar, o Parquet oferece melhor compactação e desempenho ao lidar com grandes volumes de dados.
Por conta desses benefícios, muitas soluções de análise de dados oferecem suporte à leitura de arquivos Parquet, especialmente soluções em nuvem.
Poder utilizar ferramentas avançadas de análise e inteligência de dados sobre o conteúdo armazenado pelo EPM pode representar grandes benefícios para a empresa, considerando a vasta oferta de soluções poderosas disponíveis no mercado — além da possibilidade de integrar e relacionar informações do EPM com dados de outros sistemas em lógicas extremamente robustas.
Consultando e exportando os dados
Uma maneira fácil de configurar a consulta é criar um DatasetAnalysis na pasta Server para consultar os dados do EPM. Dessa forma, é possível configurar as variáveis e agregações uma única vez e apenas ajustar o período para consultar, por exemplo, sempre os dados do último dia.
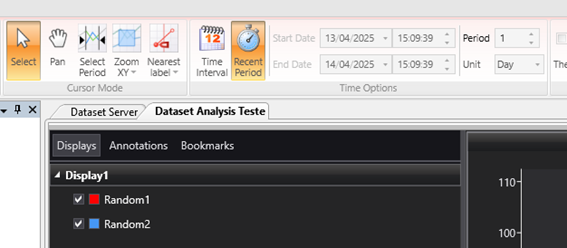
Para executar a consulta e exportar os dados, podemos utilizar o EPM Processor, com um código que será executado uma vez por dia.
Utilizaremos a biblioteca pandas para formatar os dados como um DataFrame e exportá-los para o formato Parquet. Por isso, é necessário instalar essa biblioteca em “Python Libs” no EPM Processor.
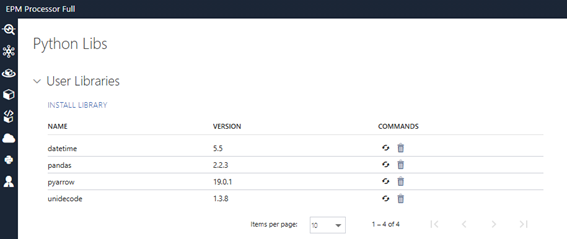
O código de exemplo receberá três parâmetros:
-
epmConnection: objetoepmconnectioncriado na área administrativa do EPM Processor; -
dsName: nome do Dataset de onde os dados serão obtidos; -
saveTo: caminho para salvar o arquivo Parquet gerado (pode ser um caminho do OneDrive ou Google Drive, por exemplo). Deve ser informado com barras (“/”) em vez de contrabarras (“”) — por exemplo:C:/MyFolder.
O processo será dividido em três etapas:
-
Executar o Dataset;
-
Converter o resultado do Dataset em um
DataFramedo Pandas; -
Exportar o
DataFramepara um arquivo Parquet.
Observe o código abaixo:
#mandatory import
import epmprocessor as epr
import pandas as pd
import datetime as dt
@epr.applicationMethod('Export to Parquet')
def exportparquet(epmConnection, dsName, saveTo = 'C:/'):
dsConfig = epmConnection.loadDatasetServer(dsName)
datavar = dsConfig.execute()
df_list = {}
for var in datavar:
new_Quality = datavar[var] [ : ] ['Quality'].byteswap().newbyteorder()
new_Timestamp = datavar[var] [ : ] ['Timestamp']
new_Value = datavar[var] [ : ] ['Value'].byteswap().newbyteorder()
d = {'VarName': var, 'Value':new_Value, 'Timestamp':new_Timestamp, 'Quality':new_Quality}
df_list[var] = pd.DataFrame(d)
invChar = ['<','>','$','#','.',',',' ','´','@','/','+',':']
pFileName = ''
for letter in 'Dataset_{}_{}'.format(dsName, dt.datetime.now().strftime("%Y-%m-%d %H:%M:%S")):
if letter in invChar:
letter = '_'
pFileName += letter
finalData = pd.concat(df_list).reset_index(drop=True)
finalData.to_parquet('{}/{}.parquet'.format(saveTo, pFileName))
Ao executar este código, será criado um arquivo Parquet no local informado, contendo o resultado do Dataset.
Como o nosso Dataset está configurado para retornar os dados do último dia, em seguida faremos o deploy do código criado.
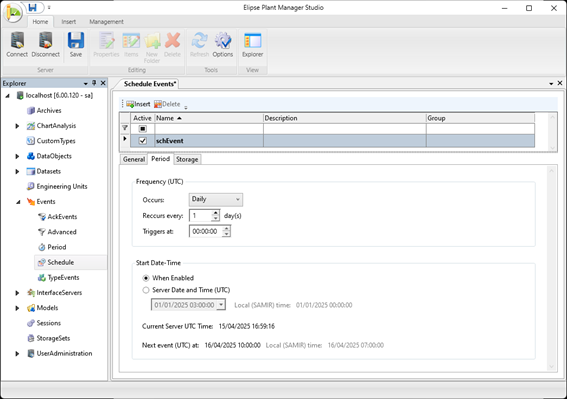
Depois, será necessário criar um evento do tipo Schedule no EPM Studio, configurado para ser disparado todos os dias à meia-noite.
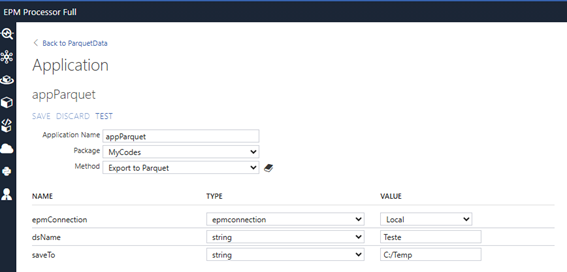
Em seguida, vamos criar uma Application no EPM Processor para configurar a chamada do código que acabamos de desenvolver.
Por fim, vamos criar uma Solution e, nela, inserir a nossa Application recém-criada em “Productions”, para que seja executada automaticamente a partir do evento que configuramos.
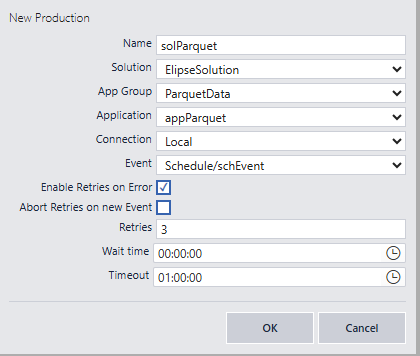
A partir dessa configuração, todos os dias, à meia-noite, o código que criamos será executado, com até três tentativas em caso de erro.
Dessa forma, serão gerados arquivos diários que poderão ser utilizados por outras soluções de análise de dados.
