INTRODUÇÃO
Clique aqui para visualizar este artigo no seu formato original, utilizando o Jupyter (IPython Notebook).
NOTA: A versão de demonstração do EPM tem as seguintes características:
- Limite de 20 variáveis (Basic Variables e/ou Expressing Variables)
- Interface de comunicação com servidores OPC DA Classic
- Interface de comunicação com servidores de Bancos de Dados Relacionais (suporte OLEDB)
- Interface de comunicação WMI (leitura de indicadores de desempenho do computador e sistema operacional Windows – WMI)
- Interface de comunicação nativa com o Elipse E3 e Elipse Power
- Interface de geradora de dados aleatórios
- Sem restrições ao número de usuários conectados simultaneamente
Passo 1: Carregando módulos para análises e visualização dos resultados
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import datetime as dt
from scipy import stats
# EPM SDK emlinguagem Python
import epmsdk
import epmsdk.communication as epmcomm
import epmsdk.dataaccess as epmda
import epmsdk.historicaldata as epmhda
Passo 2: Estabelecendo conexão com um EPM Server
SrvEntryName = ‘machine_01’ # nome da máquina onde está instalado o EPM Server
UserAuthName = ‘user_01’ # nome do usuário para a conexão
UserAuthPass = ‘MyPass_01’ # senha do usuário para a conexão
ConnectionArgs = (None, None, SrvEntryName, UserAuthName, UserAuthPass,)
try:
diliSrv = epmcomm.epmConnect(*ConnectionArgs)
print ‘Succeeded!’
except epmsdk.EpmException as ex:
print ‘Connection error: {}’.format(epmsdk.EpmExceptionCode[ex.Code])
print ‘Details: {!r}’.format(ex)
raw_input(‘Program should stop now!’)
exit(1)
Output: Succeeded!
Passo 3: Definindo um período de consulta e os nomes das variáveis de interesse
# Definição de um período para consulta
iniTime = dt.datetime(2014, 12, 1)
endTime = dt.datetime(2015, 1, 1)
queryPeriod = epmhda.TimePeriod(iniTime, endTime)
# Definição dos nomes variáveis no ambiente Python relacionadas às Basic Varibales do EPM Server
do10Adm = ‘ADMTemperature’
do10TI = ‘TI_Temperature’
do10Meeting = ‘MeetingRoom10th_Temperature’
do10Epm = ‘EPMDevTemperature’
do11Power = ‘PowerDev_Temperature’
do11TiSrv = ‘TIServidores_Temperature’
do11Meeting = ‘MeetingRoom11th_Temperature’
do11E3 = ‘E3DevTemperature’
do12Audit = ‘Auditorio_Temperature’
do12Trein = ‘Treinamento_Temperature’
do12Meeting = ‘MeetingRoom12th_Temperature’
do12Dev = ‘Dev12th_Temperature’
doTempPoa = ‘TempRS’
# Definição dos parâmetros para consulta com agregação
processInterval = dt.timedelta(minutes=30)
timeAverageAggreg = epmhda.AggregateDetails(interval=processInterval, type=epmhda.AggregateType.TimeAverage)
print ‘Definitions OK!’
Output: Definitions OK!
Passo 4: Criando objetos (variáveis do EPM) no Python e executando consultas do tipo Aggregation para o período solicitado e com o intervalo de processamento previamente definido
# Composição dos objetos: T_XX_Y – XX andar e Y é a posição da sala (frente para trás) (1.adm|2.TI|3.Meet|4.epm)
try:
# andar: 10
T10_1 = epmda.epmGetDataObject(diliSrv, do10Adm)
T10_2 = epmda.epmGetDataObject(diliSrv, do10TI)
T10_3 = epmda.epmGetDataObject(diliSrv, do10Meeting)
T10_4 = epmda.epmGetDataObject(diliSrv, do10Epm)
# andar: 11
T11_1 = epmda.epmGetDataObject(diliSrv, do11Power)
T11_2 = epmda.epmGetDataObject(diliSrv, do11TiSrv)
T11_3 = epmda.epmGetDataObject(diliSrv, do11Meeting)
T11_4 = epmda.epmGetDataObject(diliSrv, do11E3)
# andar: 12
T12_1 = epmda.epmGetDataObject(diliSrv, do12Audit)
T12_2 = epmda.epmGetDataObject(diliSrv, do12Trein)
T12_3 = epmda.epmGetDataObject(diliSrv, do12Meeting)
T12_4 = epmda.epmGetDataObject(diliSrv, do12Dev)
# Temp Porto Alegre
TPoa = epmda.epmGetDataObject(diliSrv, doTempPoa)
# Consultas
h01 = epmhda.epmTagHistoryReadAggregate(T10_1, timeAverageAggreg, queryPeriod)
h02 = epmhda.epmTagHistoryReadAggregate(T10_2, timeAverageAggreg, queryPeriod)
h03 = epmhda.epmTagHistoryReadAggregate(T10_3, timeAverageAggreg, queryPeriod)
h04 = epmhda.epmTagHistoryReadAggregate(T10_4, timeAverageAggreg, queryPeriod)
h05 = epmhda.epmTagHistoryReadAggregate(T11_1, timeAverageAggreg, queryPeriod)
h06 = epmhda.epmTagHistoryReadAggregate(T11_2, timeAverageAggreg, queryPeriod)
h07 = epmhda.epmTagHistoryReadAggregate(T11_3, timeAverageAggreg, queryPeriod)
h08 = epmhda.epmTagHistoryReadAggregate(T11_4, timeAverageAggreg, queryPeriod)
h09 = epmhda.epmTagHistoryReadAggregate(T12_1, timeAverageAggreg, queryPeriod)
h10 = epmhda.epmTagHistoryReadAggregate(T12_2, timeAverageAggreg, queryPeriod)
h11 = epmhda.epmTagHistoryReadAggregate(T12_3, timeAverageAggreg, queryPeriod)
h12 = epmhda.epmTagHistoryReadAggregate(T12_4, timeAverageAggreg, queryPeriod)
hpoa = epmhda.epmTagHistoryReadAggregate(TPoa, timeAverageAggreg, queryPeriod)
print ‘Succeeded!’
except epmsdk.EpmException as ex:
print ‘Sample failed with error: {}’.format(epmsdk.EpmExceptionCode[ex.Code])
print ‘Details: {!r}’.format(ex)
raw_input(‘Program should stop now!’)
exit(1)
Output: Succeeded!
# Imprimindo alguns resultados para verificação
print ‘Numero de pontos: {}’.format(len(hpoa))
print ‘Primeiro ponto: {0:2.2f} {1:} {2:}’.format(hpoa[‘Value’][0], hpoa[‘Timestamp’][0], hpoa[‘Quality’][0])
# Vetor com os indices das datas
dates = pd.date_range(str(hpoa[‘Timestamp’][0]), periods=len(hpoa), freq=’30min’)
print dates
Output: Numero de pontos: 1488
Primeiro ponto: 27.01 2014-12-01 00:00:00 Good
DatetimeIndex([‘2014-12-01 00:00:00’, ‘2014-12-01 00:30:00’,
‘2014-12-01 01:00:00’, ‘2014-12-01 01:30:00’,
‘2014-12-01 02:00:00’, ‘2014-12-01 02:30:00’,
‘2014-12-01 03:00:00’, ‘2014-12-01 03:30:00’,
‘2014-12-01 04:00:00’, ‘2014-12-01 04:30:00’,
…
‘2014-12-31 19:00:00’, ‘2014-12-31 19:30:00’,
‘2014-12-31 20:00:00’, ‘2014-12-31 20:30:00’,
‘2014-12-31 21:00:00’, ‘2014-12-31 21:30:00’,
‘2014-12-31 22:00:00’, ‘2014-12-31 22:30:00’,
‘2014-12-31 23:00:00’, ‘2014-12-31 23:30:00′],
dtype=’datetime64[ns]’, length=1488, freq=’30T’)
Passo 5: Criando um DataFrame do módulo Pandas para facilitar análises
# Construção do DataFrame – série temporal
data = {‘TPoa’: hpoa[‘Value’].tolist(),
‘T10_1’: h01[‘Value’].tolist(), ‘T10_2’: h02[‘Value’].tolist(), ‘T10_3’: h03[‘Value’].tolist(), ‘T10_4’: h04[‘Value’].tolist(),
‘T11_1’: h05[‘Value’].tolist(), ‘T11_2’: h06[‘Value’].tolist(), ‘T11_3’: h07[‘Value’].tolist(), ‘T11_4’: h04[‘Value’].tolist(),
‘T12_1’: h09[‘Value’].tolist(), ‘T12_2’: h10[‘Value’].tolist(), ‘T12_3’: h11[‘Value’].tolist(), ‘T12_4’: h12[‘Value’].tolist(),
}
dfRaw = pd.DataFrame(data, index=dates)
# Remove Nan’s
df = dfRaw.dropna()
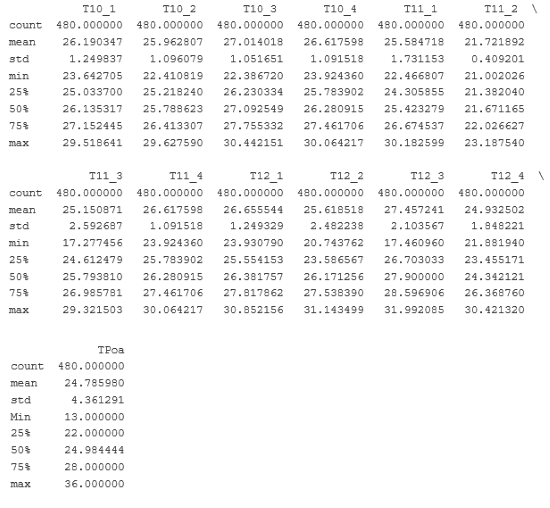
df.describe()
Output:
Passo 6: Visualizando graficamente alguns resultados
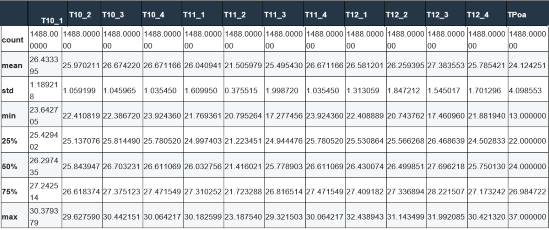
# Gráfico com as tendências
df.plot()
plt.gcf().set_size_inches(18,8)
plt.legend(loc=’best’)
Output:
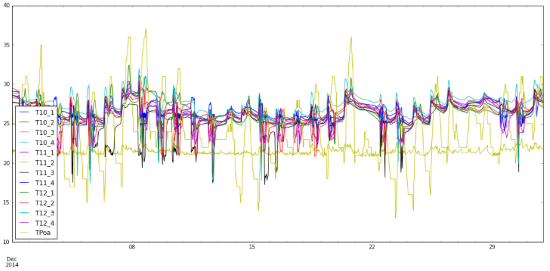
# Gráfico das médias mensais
dfm = df.mean()
dfm.plot(kind=’bar’, colormap=’coolwarm’)
plt.gcf().set_size_inches(18,8)
Output:
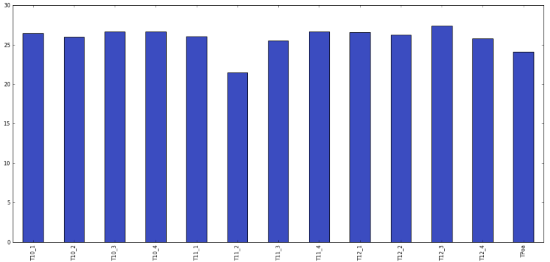
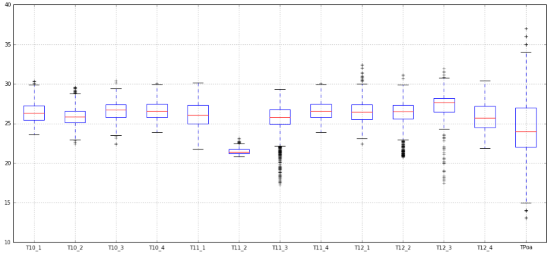
# Fazer um boxplot
df.boxplot()
plt.gcf().set_size_inches(18,8)
Output: C:\Anaconda2\lib\site-packages\ipykernel\__main__.py:2: FutureWarning:
The default value for ‘return_type’ will change to ‘axes’ in a future release.
To use the future behavior now, set return_type=’axes’.
To keep the previous behavior and silence this warning, set return_type=’dict’.
from ipykernel import kernelapp as app
# Para salvar em um arquivo CSV
df.to_csv(r’C:\Users\mauricio\Desktop\ElipseTemps.csv’, sep=’;’, float_format=’%.3f‘)
print ‘Arquivo ElipseTemps.csv salvo no desktop!’
Output: Arquivo ElipseTemps.csv salvo no desktop!
# Contagem de todos valores com temperaturas entre 22 e 24 °C
Crit1 = df >= 22.0
Crit2 = df <=24.0
allCrit = AllCrit = Crit1 & Crit2
df[allCrit].count()
Output: T10_1 1
T10_2 10
T10_3 6
T10_4 1
T11_1 165
T11_2 180
T11_3 87
T11_4 1
T12_1 6
T12_2 86
T12_3 8
T12_4 283
TPoa 464
dtype: int64
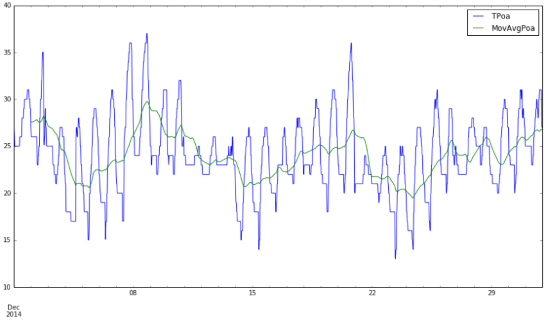
# Cálculo da média móvel e gráfico
mAvgPoa = pd.rolling_mean(df[‘TPoa’], 50)
df.TPoa.plot(label=’TPoa’)
mAvgPoa.plot(label=’MovAvgPoa’)
plt.legend()
plt.gcf().set_size_inches(15,8)
Output:
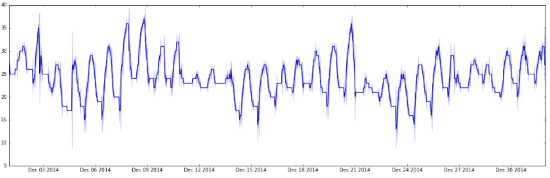
# Grafico temperatura media diaria de Porto Alegre, da sua media a cada 2 dias e banda baseada em 2 desvios padrão
ma = pd.rolling_mean(df.TPoa, 2)
mstd = pd.rolling_std(df.TPoa, 2)
plt.figure(figsize=(20,6), dpi=300)
plt.plot(df.index, df.TPoa, ‘k’)
plt.plot(ma.index, ma, ‘b’)
plt.fill_between(mstd.index, ma-2*mstd, ma+2*mstd, color=’b’, alpha=0.2)
Output:
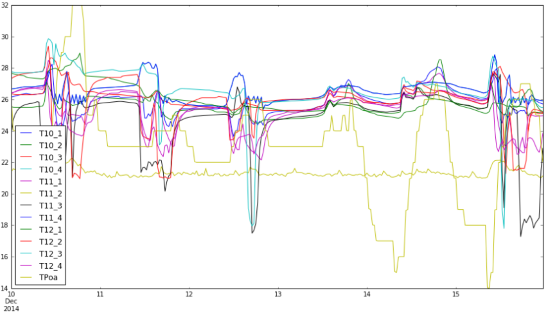
Passo 7: Análises em períodos específicos – consultas a intervalos de tempo definidos em tempo de consulta
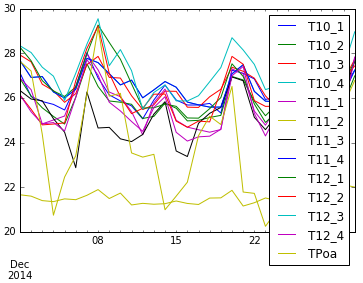
# Condições nos dias 10 a 15
df.ix[‘2014-12-10′:’2014-12-15’].plot(figsize = (15, 8))
Output:
# Reamostrando os dados em base diária
df.resample(‘D’, how=’mean’).plot()
Output:
# Pegando dados de dias específicos
getDates = [dt.datetime(2014, 12, 1), dt.datetime(2014, 12, 7), dt.datetime(2014, 12, 9)]
index = pd.DatetimeIndex(getDates)
print index
df.ix[index]
Output: DatetimeIndex([‘2014-12-01’, ‘2014-12-07’, ‘2014-12-09′], dtype=’datetime64[ns]’, freq=None)

# Pegando os dados apenas dentro do período das 8:30 às 18:00 dos dias úteis
spanB = pd.period_range(df.index[0], df.index[-1], freq=’B’) # apenas dias úteis
iniT = spanB[0].to_timestamp() + dt.timedelta(hours=8, minutes=30)
endT = spanB[0].to_timestamp() + dt.timedelta(hours=18)
dfW = df.ix[iniT:endT]
for day in spanB:
iniT = day.to_timestamp() + dt.timedelta(hours=8, minutes=30)
endT = day.to_timestamp() + dt.timedelta(hours=18)
dfW = dfW.append(df.ix[iniT:endT])
print dfW.describe()
Output: